MongoDB
#认识 MongoDB
#基本概念
#什么是 MongoDB
一个以 json 为数据模型的文档数据库;文档来自于 “JSON Document”,并非我们理解的 PDF、word 文档;类似于 Oracle、MySQL 海量数据处理,数据平台
#MongoDB 是免费的吗?
- MongoDB 有两个发布版本:社区版和企业版
- 社区办基于 SSPL,一种和 AGPL 基本类似的开源协议
- 企业版是基于商业协议,需要付费使用
#主要特点
- 建模为可选
- JSON 数据模型比较适合开发
- 横向扩展可以支撑很大数据量和并发
- 易扩展、高性能、高可用
- 较容易映射复杂数据(key-value)
- 无事务特性要求(ACID 特性)
- A(Atomicity): 原子性
- C(Consistency): 一致性
- I(Isolation): 独立性,也叫隔离性
- D(Durability):持久性
#MongoDB 与关系型数据库
| MongoDB | RDBMS | |
|---|---|---|
| 数据模型\ | 文档模型 | 关系模型 |
| 数据库类型\ | OLTP | OLTP |
| CRUD 操作\ | MQL/SQL | SQL |
| 高可用\ | 复制集 | 集群模式 |
| 横向扩展\ | 通过原生分片完善支持 | 数据分区或者应用侵入式 |
| 索引支持\ | B-树、全文索引、地理位置索引、多键(multikey)索引、TTL 索引 | B 树 |
| 开发难度\ | 容易 | 困难 |
| 数据容量\ | 理论上没有上限 | 千万、亿 |
| 扩展方式\ | 垂直扩展 + 水平扩展 | 垂直扩展 |
#MongoDB 的优势及特点
- 面向开发者的医用 + 高效数据库

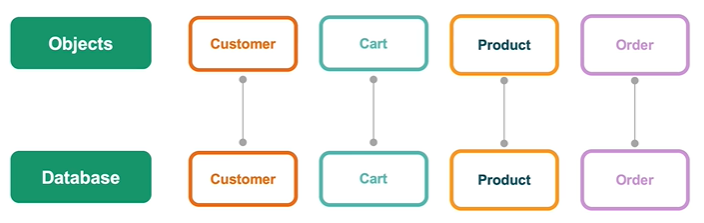
一目了然的对象模型
文档模型与数据库中的文档一一对应
- 灵活:快速响应业务变化
- 多形性:同一集合可以包含不同字段(类型)的文档对象
- 动态性:线上修改数据模式,修改时应用与数据库均无需下线
- 数据治理:支持使用 JSON Schema 来规范数据模式,在保障模式灵活动态的前提下,提供数据治理能力

- 快速:最简单快速的开发方式;JSON 模型之快速特性:
- 数据库引擎只需要在一个存储区读写
- 反范式、无关联的组织极大优化查询速度
- 程序 API 自然开发快速

- 原生的高可用和横向扩展能力
- Replica Set-2 to 50 个成员
- 自恢复
- 多中心容灾能力
- 滚动服务 - 最小化服务终端
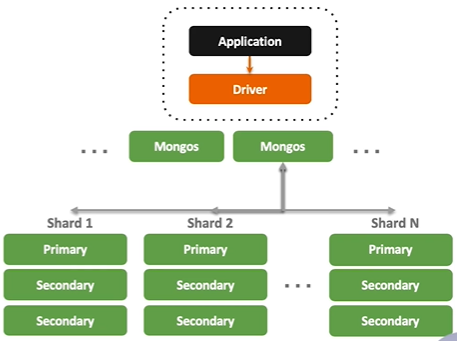
- 横向扩展能力
- 需要的时候无缝扩展
- 应用全透明
- 多种数据分布策略
- 轻松支持 TB-PB 数量级
#安装 MongoDB 官网(opens new window)
- 打开docker hub 官网 (opens new window)搜 mongodb
#使用 dockerfile 模式安装 mongo
|
以我的的服务为例,在 home 文件夹下创建一个 mongotest 文件,然后在里面创建一个 docker-compose.yml,然后将上面的内容复制到 docker-compose.yml 文件中(当然也可以使用 ftp 工具上传)
我这儿就用 vim 编辑 docker-compose.yml 文件
|
然后就将内容复制进去,按ESC,然后在分别按:wq回车
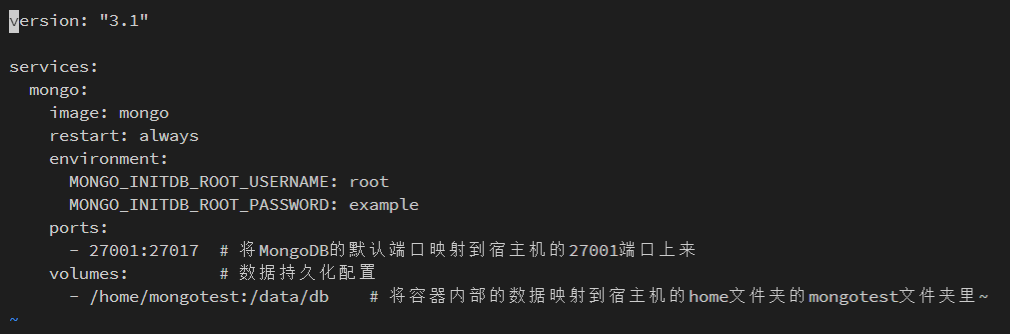
#启动mongo服务
现在就可以使用docker-compose up -d来启动 mongo 服务了,执行命令后 docker 就去拉去 mongo 镜像并创建 mongo 数据
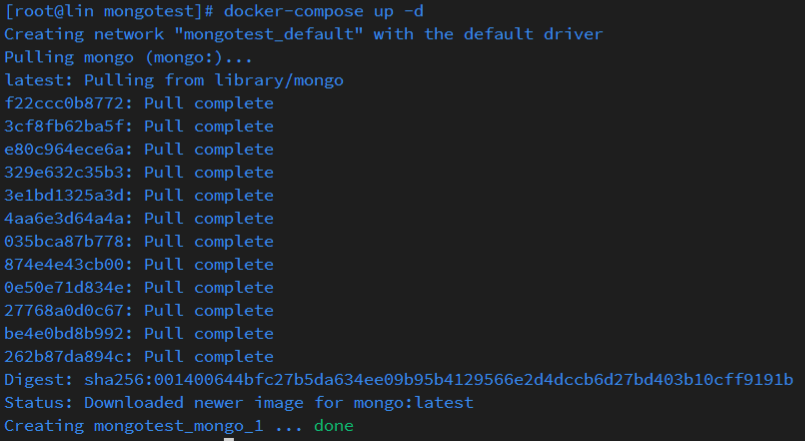
#查看运行进程
可以使用docker ps -a或者docker-compose查看现在已启动的 docker 镜像

#配置开放端口
连接前一定要检查宿主机端口是否开放,centOS 可以使用firewall-cmd --add-port=27017/tcp --permanent命令添加端口,添加完成后,重启安全组,命令:firewall-cmd --reload

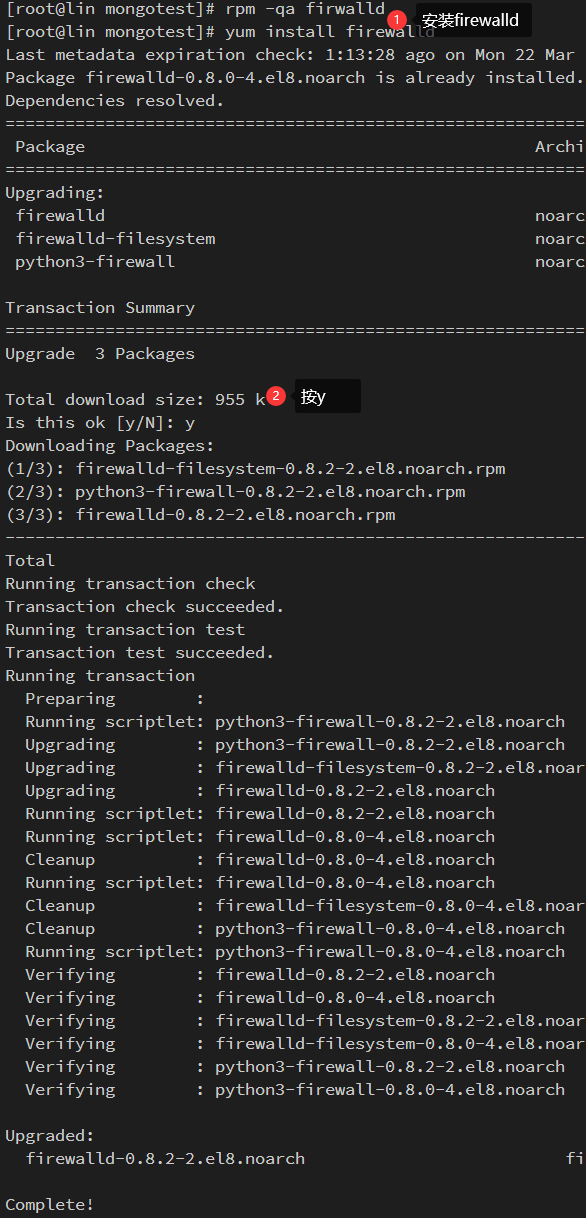
如果在添加规则的时候出现如下报错的话,可有一下方案解决

- 检查服务器是否有安装
firewalld,检查命令如下:
|
- 安装 firewalld 的命令:
|
#创建用户并分配权限
#角色说明
以下是MongoDB中内置的角色:
#数据库用户角色(Database User Roles) - 常用
- read
read角色包含读取所有非系统集合数据和订阅部分系统集合(system.indexes、system.js、system.namespaces)的权限。
该角色权限包含命令操作:changeStream、collStats、dbHash、dbStats、find、killCursors、listIndexes、listCollections。
- readWrite
readWrite角色包含read角色的权限同时增加了对非系统集合数据的修改权限,但只对系统集合system.js有修改权限。
该角色权限包含命令操作:collStats、convertToCapped、createCollection、dbHash、dbStats、dropCollection、createIndex、dropIndex、find、insert、killCursors、listIndexes、listCollections、remove、renameCollectionSameDB、update。
#数据库管理角色(Database Administration Roles) - 常用
- dbAdmin
dbAdmin角色包含执行某些管理任务(与schema相关、索引、收集统计信息)的权限,该角色不包含用户和角色管理的权限。
对于系统集合(system.indexes、system.namespaces、system.profile)包含命令操作:collStats、dbHash、dbStats、find、killCursors、listIndexes、listCollections、dropCollection and createCollection(仅适用system.profile)
对于非系统集合包含命令操作:bypassDocumentValidation、collMod、collStats、compact、convertToCapped、createCollection、createIndex、dbStats、dropCollection、dropDatabase、dropIndex、enableProfiler、reIndex、renameCollectionSameDB、repairDatabase、storageDetails、validate
- dbOwner
dbOwner角色包含对数据所有的管理操作权限。即包含角色readWrite、dbAdmin和userAdmin的权限。
- userAdmin
userAdmin角色包含对当前数据库创建和修改角色和用户的权限。该角色允许向其它任何用户(包括自身)授予任何权限,所以这个角色也提供间接对超级用户(root)的访问权限,如果限定在admin数据中,也包括集群管理的权限。
该角色权限包含命令操作:changeCustomData、changePassword、createRole、createUser、dropRole、dropUser、grantRole、revokeRole、setAuthenticationRestriction、viewRole、viewUser。
#集群管理角色(Cluster Administration Roles)**
- clusterManager
clusterManager角色包含对集群监控和管理操作的权限。拥有此角色的用户能够访问集群中的config数据库和local数据库。
对于整个集群该角色包含命令操作:addShard、appendOplogNote、applicationMessage、cleanupOrphaned、flushRouterConfig、listSessions (3.6新增)、listShards、removeShard、replSetConfigure、replSetGetConfig、replSetGetStatus、replSetStateChange、resync。
对于集群中所有的数据库包含命令操作:enableSharding、moveChunk、splitChunk、splitVector。
对于集群中config数据库和local数据库包含的命令操作可以参考官方文档:https://docs.mongodb.com/manual/reference/built-in-roles/#clusterManager (opens new window)。
- clusterMonitor
clusterMonitor角色包含针对监控工具具有只读操作的权限。如工具MongoDB Cloud Manager和工具Ops Manager。
对于整个集群该角色包含命令操作:checkFreeMonitoringStatus(4.0新增)、connPoolStats、getCmdLineOpts、getLog、getParameter、getShardMap、hostInfo、inprog、listDatabases、listSessions (3.6新增)、listShards、netstat、replSetGetConfig、replSetGetStatus、serverStatus、setFreeMonitoring (4.0新增)、shardingState、top。
对于集群中所有的数据为包含命令操作:collStats、dbStats、getShardVersion、indexStats、useUUID(3.6新增)。
对于集群中config数据库和local数据库包含的命令操作可以参考官方文档:https://docs.mongodb.com/manual/reference/built-in-roles/#clusterMonitor (opens new window)。
- hostManager
hostManager角色包含针对数据库服务器的监控和管理操作权限。
对于整个集群该角色包含命令操作:applicationMessage、closeAllDatabases、connPoolSync、cpuProfiler、flushRouterConfig、fsync、invalidateUserCache、killAnyCursor (4.0新增)、killAnySession (3.6新增)、killop、logRotate、resync、setParameter、shutdown、touch、unlock。
对于集群中所有的数据库包含命令操作:killCursors、repairDatabase。
- clusterAdmin
clusterAdmin角色包含MongoDB集群管理最高的操作权限。该角色包含clusterManager、clusterMonitor和hostManager三个角色的所有权限,并且还拥有dropDatabase操作命令的权限。
#备份和恢复角色(Backup and Restoration Roles) - 常用
- backup
backup角色包含备份MongoDB数据最小的权限。
对于MongoDB中所有的数据库资源包含命令操作:listDatabases、listCollections、listIndexes。
对于整个集群包含命令操作:appendOplogNote、getParameter、listDatabases。
对于以下数据库资源提供find操作权限:
- 对于集群中的所有非系统集合,包括自身的config数据库和local数据库;
- 对于集群中的系统集合:system.indexes、system.namespaces、system.js和system.profile;
- admin数据库中的集合:admin.system.users和admin.system.roles;
- config.settings集合;
- 2.6版本之前的system.users集合。
对于config.setting集合还有insert和update操作权限。
- restore
restore角色包含从备份文件中还原恢复MongoDB数据(除了system.profile集合)的权限。
restore角色有以下注意事项:
- 如果备份中包含system.profile集合而恢复目标数据库没有system.profile集合,mongorestore会尝试重建该集合。因此执行用户需要有额外针对system.profile集合的createCollection和convertToCapped操作权限;
- 如果执行mongorestore命令时指定选项
--oplogReplay,则restore角色包含的权限无法进行重放oplog。如果需要进行重放oplog,则需要只对执行mongorestore的用户授予包含对实例中任何资源具有任何权限的自定义角色。
对于整个集群包含命令操作:getParameter。
对于所有非系统集合包含命令操作:bypassDocumentValidation、changeCustomData、changePassword、collMod、convertToCapped、createCollection、createIndex、createRole、createUser、dropCollection、dropRole、dropUser、grantRole、insert、revokeRole、viewRole、viewUser。
关于restore角色包含其它的命令操作可以参考官方文档:https://docs.mongodb.com/manual/reference/built-in-roles/#restore (opens new window)。
#全数据库级角色(All-Database Roles)
以下角色只存在于admin数据库,并且适用于除了config和local之外所有的数据库。
- readAnyDatabase
readAnyDatabase角色包含对除了config和local之外所有数据库的只读权限。同时对于整个集群包含listDatabases命令操作。
在MongoDB3.4版本之前,该角色包含对config和local数据库的读取权限。当前版本如果需要对这两个数据库进行读取,则需要在admin数据库授予用户对这两个数据库的read角色。
- readWriteAnyDatabase
readWriteAnyDatabase角色包含对除了config和local之外所有数据库的读写权限。同时对于整个集群包含listDatabases命令操作。
在MongoDB3.4版本之前,该角色包含对config和local数据库的读写权限。当前版本如果需要对这两个数据库进行读写,则需要在admin数据库授予用户对这两个数据库的readWrite角色。
- userAdminAnyDatabase
userAdminAnyDatabase角色包含类似于userAdmin角色对于所有数据库的用户管理权限,除了config数据库和local数据库。
对于集群包含命令操作:authSchemaUpgrade、invalidateUserCache、listDatabases。
对于系统集合admin.system.users和admin.system.roles包含命令操作:collStats、dbHash、dbStats、find、killCursors、planCacheRead、createIndex、dropIndex。
该角色不会限制用户授予权限的操作,因此,拥有角色的用户也有可能授予超过角色范围内的权限给自己或其它用户,也可以使自己成为超级用户,userAdminAnyDatabase角色也可以认为是MongoDB中的超级用户角色。
- dbAdminAnyDatabase
dbAdminAnyDatabase角色包含类似于dbAdmin角色对于所有数据库管理权限,除了config数据库和local数据库。同时对于整个集群包含listDatabases命令操作。
在MongoDB3.4版本之前,该角色包含对config和local数据库的管理权限。当前版本如果需要对这两个数据库进行管理,则需要在admin数据库授予用户对这两个数据库的dbAdmin角色。
#超级用户角色(Superuser Roles)
WARNING
慎用
以下角色包含在任何数据库授予任何用户任何权限的权限。这意味着用户如果有以下角色之一可以为自己在任何数据库授予任何权限。
- dbOwner角色(作用范围为admin数据库)
- userAdmin角色(作用范围为admin数据库)
- userAdminAnyDatabase角色
以下角色包含数据库所有资源的所有操作权限。
- root
root角色包含角色readWriteAnyDatabase、dbAdminAnyDatabase、userAdminAnyDatabase、clusterAdmin、restore和backup联合之后所有的权限。
#内部角色(Internal Role)
- __system
MongoDB将此角色授予代表集群成员的用户对象,如副本集(replica set)成员或mongos实例。该角色允许用户对于需要的数据库操作都具有相应的权限,不要将该角色授予应用程序用户或其它管理员用户。
#总结说明
通过以上对内置角色的说明,总结一下较为常用的内置角色,如下表:
| 角色 | 权限描述 |
|---|---|
| read | 可以读取指定数据库中任何数据。 |
| readWrite | 可以读写指定数据库中任何数据,包括创建、重命名、删除集合。 |
| readAnyDatabase | 可以读取所有数据库中任何数据(除了数据库config和local之外)。 |
| readWriteAnyDatabase | 可以读写所有数据库中任何数据(除了数据库config和local之外)。 |
| dbAdmin | 可以读取指定数据库以及对数据库进行清理、修改、压缩、获取统计信息、执行检查等操作。 |
| dbAdminAnyDatabase | 可以读取任何数据库以及对数据库进行清理、修改、压缩、获取统计信息、执行检查等操作(除了数据库config和local之外)。 |
| clusterAdmin | 可以对整个集群或数据库系统进行管理操作。 |
| userAdmin | 可以在指定数据库创建和修改用户。 |
| userAdminAnyDatabase | 可以在指定数据库创建和修改用户(除了数据库config和local之外)。 |
#创建自定义角色
#查看环境
TIP
这里要注意imooc用户是imooc数据库的imooc角色
|
目前的权限情况
|
#查看自定义的角色
|
#更新自定义的角色
为自定义角色imooc更新集合imooc.rights的insert权限。
|
#添加角色权限
为自定义角色imooc添加集合imooc.rights的remove权限。
|
#删除角色
为自定义角色imooc收回集合imooc.users的update权限。
|
#创建用户并分配角色
|
#查看用户信息
|
#为用户添加角色
|
#删除用户
|
#更改用户密码
|
#开启MongoDB的访问控制
要开启访问控制,则需要在mongod进程启动时加上选项--auth或在启动配置文件加入选项auth=true,并重启mongodb实例(使用docker开启的同学不用管)
|
#MongoDB交互终端
#直装方式
登录MongoDB实例
使用mongo shell登录mongodb实例:
|
打印:
|
#docker方式
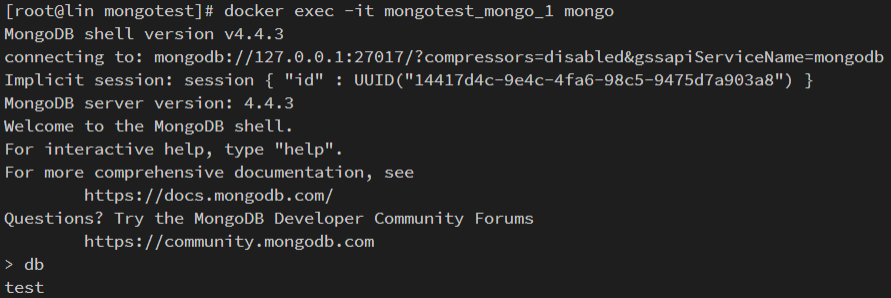
交互式终端命令
|
- 查看 mongo 镜像的运行时的镜像名
|

docker 中连接 mongo
- 连接示例
- 切换数据库

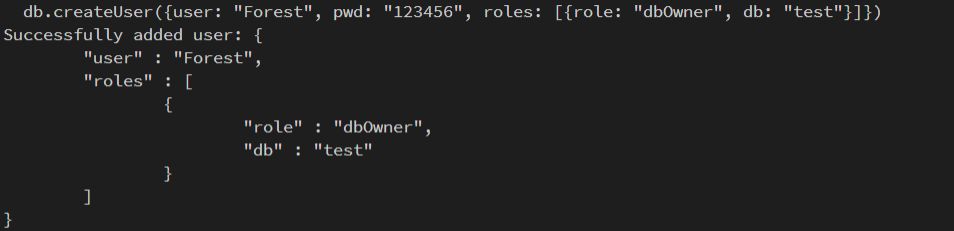
- 添加账号密码, 返回为 1 就成功了

- 查看全部数据库

- 切换到 admin 数据库,创建一个用户
|
上列图示环境
- system:CentOS 8.2 64 位
- CPU&内存:1 核 2 GiB
- docker: 19.03.14
#基本操作
#数据库相关
#查看已有的数据库
|

#查看当前数据库
|

#创建数据库或者切换数据库
|

#查看当前数据库已有文档(表)
|

#删除数据库 dropDatabase
- 使用
db.dropDatabase()来删除数据库 - 数据库相应的文件也会被删除,磁盘空间将被释放
|
#增删改查CURD操作
#添加数据
语法\:
|
- 添加一条数据

- 添加多条数据

#查看文档模型中的数据
find()是 MongoDB 数据库查询数据的基本指令,相当于 SQL 中的SELECTfind()返回游标
查询指定文档模型中的全部数据
$ db.<文档模型的名称>.find()
单条件查询
查询一条 name 为 apple 的数据

多条件
and查询查询一条 name 为 pear 和 weight 为 400 的数据

and的另一种形式查询
多条件
or查询查询 name 为 apple 或者 weight 为 400 的数据

按正则表达式查找
查找所有 name 中以 a 开头的所有数据

查询条件对照表
| 逻辑运算符\ | MongoDB 中的写法\ |
|---|---|
| a 等于 1 | { a : 1 } |
| a 不等于 1 | { a : { $ne : 1 } } |
| a 大于 1 | { a : { $gt: 1 } } |
| a 小于 1 | { a : { $lt : 1 } } |
| a 大于等于 1 | { a : { $gte : 1 } } |
| a 小于等于 1 | { a : { $lte : 1 } } |
| a 等于 1 和 b 等于 1 | { a : 1, b : 1 }或者{ $and: [{ a : 1 }, { b : 1 }] } |
| a 等于 1 或者 b 等于 1 | { $or: [{ a : 1 }, { b : 1 }] } |
| 判断 a 字段不存在 | { a : { $exists : false } } |
| a 包含 1, 2, 3 | { a : { $in : [1, 2, 3] } } |
查询的逻辑运算符
- $lt 存在并小于
- $lte 存在并小于等于
- $gt 存在并大于
- $gte 存在并大于等于
- $ne 不存在或者存在但不等于
- $in 存在并在指定数组中
- $nin 不存在或者不在指定数组中
- $or 匹配两个或多个条件中的一个
- $and 匹配全部条件
#find 搜索子文档
find 支持使用“field.sub_field”的形式查询子文档。假设有一个文档:
|
#使用 find 搜索数组
find支持对数组中的元素进行搜索,假设有一个文档
|
- 在数组中搜索子对象的多个字段时,如果使用
$elemMatch,它表示必须是同一个
子对象满足多个条件。考虑以下两个查询:
|
控制 find 返回的字段
find可以指定只返回指定的字段;\_id字段必须明确指明不返回,否则默认返回;- 在 MongoDB 中我们称这为投影(projection);
|
#删除数据
remove命令需要配合查询条件使用- 匹配查询条件的文档会被删除
- 指定一个文档条件会删除所有记录
|
删除表
- 集合中的所有文档都会被删除
- 吉和相关的索引也会被删除
|
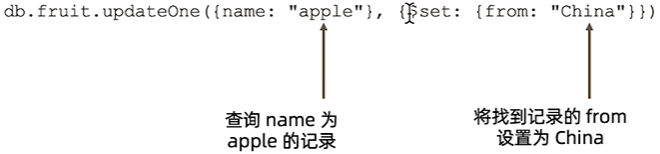
#更新数据
Update操作执行格式:db.<集合>.update(<查询条件>,<更新内容>)
TIP
使用
updateOne表示无论条件匹配多少条记录,始终只会更新一条使用
updateMany标识条件匹配多少条就更新多少条`
updateOne/updateMany
方法要求更新条件部分必须具有以下之一,否则将报错
* $set/$unset
* $push/$pushAll/$pop
* $pull/$pullAll
* $addToSet
* $push:增加一个对象到数组最后
* $pushAll:增加多个对象到数组最后
* $pop:从数组的最后删除一个对象
* $pull:如果匹配指定的值,从数组中删除相应的对象
* $pullAll:如果匹配任意的值,从数据中删除相对应的对象
* $addToSet:如果不存在则增加一个值到数组
## [#](https://front-end.toimc.com/notes-page/basic/mongo/02-基础操作.html#备份与恢复)备份与恢复
* 备份
```shell
$ mongodump -h localhost -u <用户名> -p <密码> -d <数据库名> -o <指定目录>
参数说明
- -h 指向备份服务器
- -u 用户名
- -p 密码
- -d 指定备份的数据;如果不写这个参数则备份全部数据库
-o 数据备份到那个目录
恢复
|
#高级查询
#聚合查询
#什么是 MongoDB 聚合框架
MongoDB 聚合框架(Aggregation Framework)是一个计算框架,它可以:
- 作用在一个集合或者几个集合上
- 对集合的数据进行的一些列运算
- 讲这些数据转化为期望的形式
从效果而言,聚合框架相当于 SQL 查询中的
- GROUP BY
- LEFT OUTER JOIN
- AS 等等
#管道(Pipeline)和步骤(Stage)
- 整个聚合运算过程成为管道(Pipeline),它由多个步骤组成;每个管道
- 接受一系列文档(原始数据)
- 每个步骤对这些文档进行一系列运算
- 结果文档输出给下一个步骤

|
| 步骤 | 作用 | SQL 等价运算符 |
|---|---|---|
| $match | 过滤 | WHERE |
| $project | 投影 | AS |
| $sort | 排序 | ORDER BY |
| $group | 分组 | GROUP BY |
| $skip/$limit | 结果限制 | SKIP/LIMIT |
| $looup | 左外连接 | LEFT OUTER JOIN |
| $unwind | 展开数组 | N/A |
| $graphLoopup | 图搜索 | N/A |
| $facet/$bucket | 分页搜索 | N/A |
#聚合运算的使用场景
- 计算;比如
- 计算一段时间内的销售总额、均值
- 分析一段时间的净利润
- 分析购买人的年龄分布
- 分析学生成绩分布
- 统计员工绩效
- …..
- 数据的复杂运用
#MQL 常用步骤与 SQL 对比
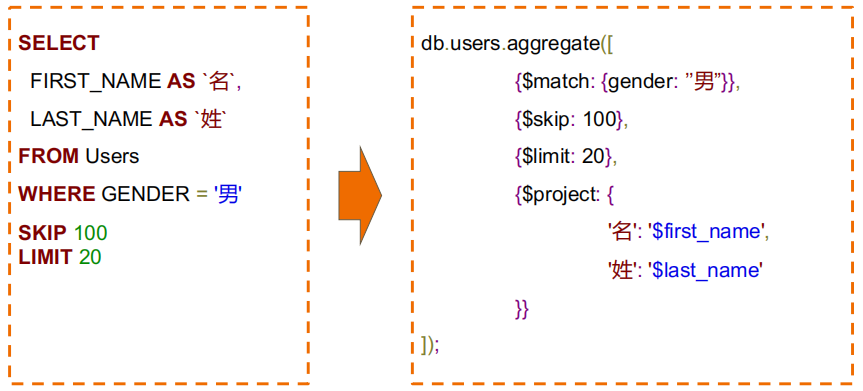
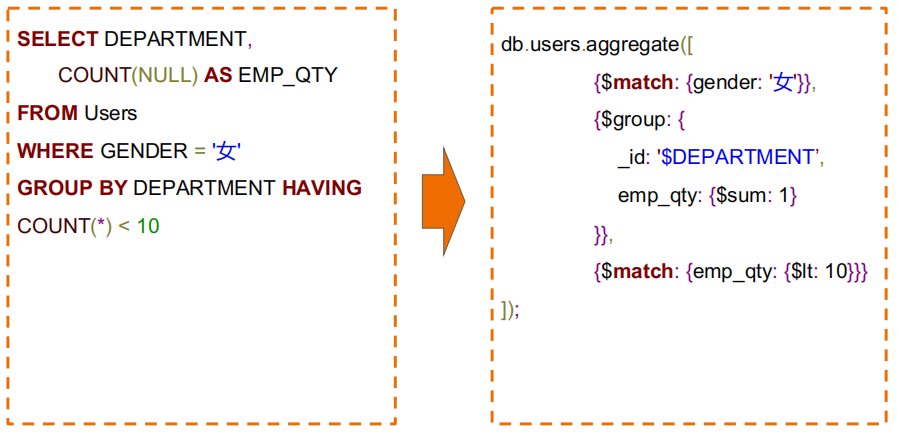
#MQL 特有步骤$unwind

#MQL 特有的$bucket
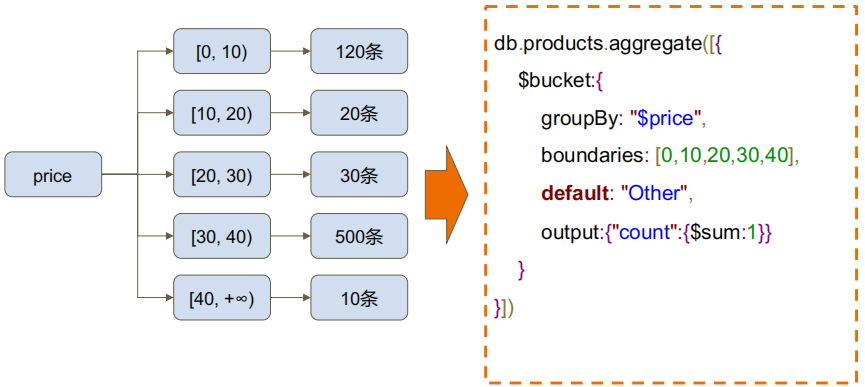
#MQL 特有的$facet
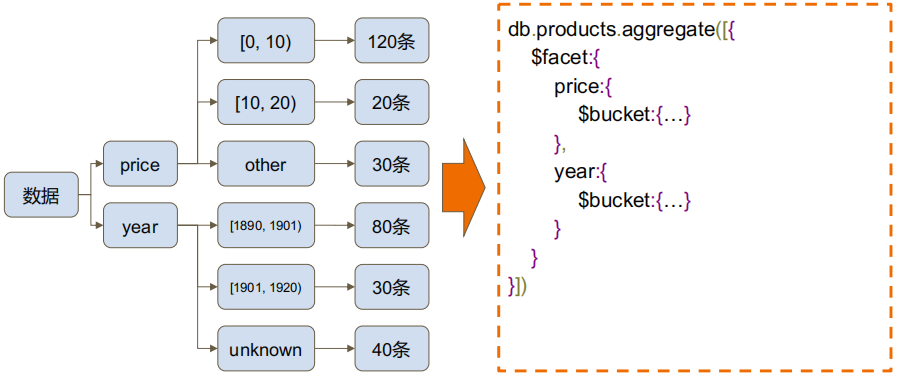
#复制集
#复制集的作用
- MongoDB 复制集的主要意义在于实现服务高可用
- 它的现实依赖于两个方面的功能
- 数据写入时将数据迅速复制到另一个独立节点上
- 在接受写入的节点发生故障是自动选举出一个新的替代节点
- 在实现高可用的同事,复制集实现了其他几个附加作用
- 数据分发:将数据从一个区域复制到另一个区域,减少另一个区域的读延迟
- 读写分离:不同类型的压力分别在不同的节点上执行
- 异地容灾:在数据中心发生故障的时候快速切换到异地
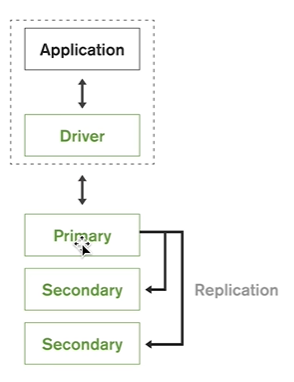
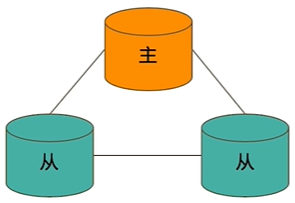
#典型复制集结构
- 一个典型的复制集由 3 个以上具有投票权的节点组成,包括:
- 一个节点(PRIMARY):接受读入操作和选举时投票
- 连个(或多个)从节点(SECONDERY):复制节点上的新数据和选举时投票
- 不推荐使用 Arbiter(投票节点)
#数据是如何复制的?
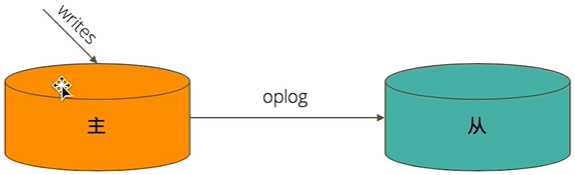
- 当一个修改操作,无论是插入、更新或者删除,达到主节点时,它对数据的操作将被记录下来(经过一系列必要的转换),这些记录被称为
oplog - 从节点通过在主节点上打开一个
tailable游标不断获取新进入直接点的oplog,并在自己的数据上回放,一次保持跟主节点的数据一致性
#选举时如何完成故障恢复的?
- 具有投票权的节点之间凉凉相互发送心跳
- 当 5 次心跳未收到时判断为节点失联(宕机、断网……)
- 如果失联的是主节点,从节点会发起选举,选出新的主节点
- 如果失恋的是从节点则不会产生新的选举
- 选举基于RAFT 一致性算法 (opens new window)实现,选举成功的必要条件是大多数投票节点存活
- 复制集中最多可以有 50 个节点,但具有投票权的节点最多 7 个
#影响选举的因素
- 整个集群必须有大多数节点存活
- 被选举为主节点的节点必须
- 能够与多数节点建立连接
- 具有较新的
oplog(操作日志) - 具有较高的优先级(如果有配置)
#常见选项
- 复制及节点有以下常见的选置项:
- 是否具有投票权(v 参数):有则参与投票(默认都有投票权)
- 优先级(priority 参数):优先级越高的节点越优先成为主节点;优先级为 0 的节点无法成为主节点
- 隐藏(hidden 参数):复制数据,但对应不可见;隐藏节点可以具有投票权,但优先级必须为 0
- 延迟(slaveDelay):复制 n 秒之前的数据,保持与主节点的时间差

#复制集注意事项
- 关于硬件
- 因为正常的复制集节点都有可能成为主节点,他们的地位是一样的,因此硬件配置上必须一致
- 为例保证节点不会同时宕机,各节点使用的硬件必须具有独立性
- 关于软件
- 复制集各节点软件版本必须一致,以避免出现不可预知的问题
- 增加节点不会增加系统写性能
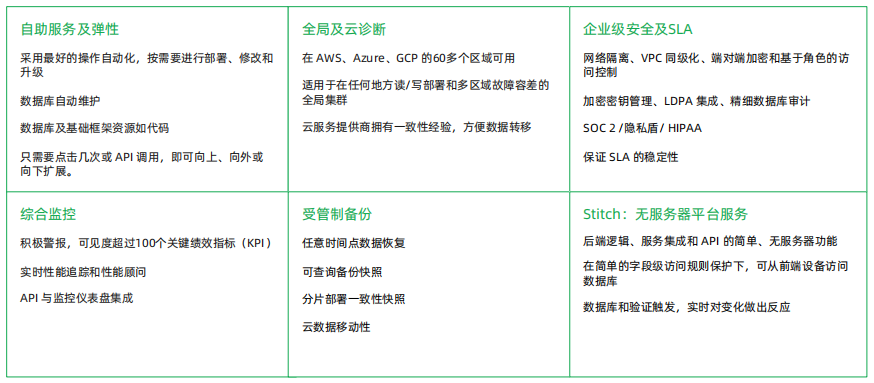
#Atlas-MongoDB 公有云托管服务