Node
Nodejs
什么是 Node.js
Node.js® is a JavaScript runtime built on Chrome’s V8 JavaScript engine.
Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境。
通俗的理解:Node.js 为 JavaScript 代码的正常运行,提供的必要的环境。
Node.js 的官网地址: https://nodejs.org/zh-cn/
Node运行时
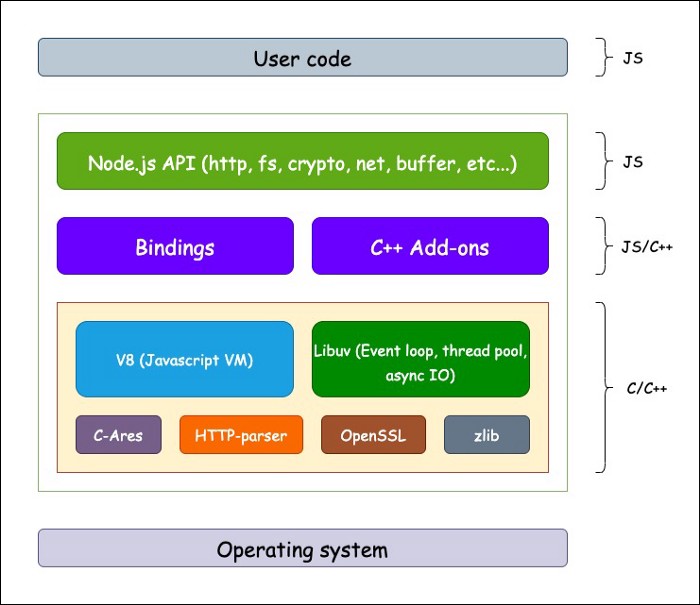
注意:
- Node.js 是 JavaScript 的
后端运行环境。(正常情况下,Nodejs要安装到服务器上) - Node.js 中无法调用 DOM 和 BOM 等 浏览器内置 API
安装Node
方案:
使用nvm(Node Version Management,node版本管理工具)安装
方式一:mac推荐使用以下命令安装,较为灵活,可以选择node版本(推荐)
用命令行安装工具前先检查一下子,用于在Mac上安装或更新的Xcode的命令行工具
xcode-select -p没安装的话先进行安装
xcode-select --install# 下载并安装 nvm:
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.3/install.sh | bash
# 代替重启 shell
\. "$HOME/.nvm/nvm.sh"
# 下载并安装 Node.js:
nvm install 24
# 验证 Node.js 版本:
node -v # Should print "v24.11.1".
# 验证 npm 版本:
npm -v # Should print "11.6.2".以上安装方式可能会导致nvm只在当前终端生效,新终端不生效,那是因为nvm未自动写入shell配置文件
配置nvm环境,找到如下位置的文件(如果没有则新建),步骤如下:
1、确认你使用的是 zsh 还是 bash
echo $SHELL
macOS 默认是 zsh(路径通常为 /bin/zsh)
如果返回:
/bin/zsh → 用 .zshrc
/bin/bash → 用 .bashrc2、查看~/.zshrc文件是否存在,不存在进行创建
cat ~/.zshrc
vi ~/.zshrc3、在文件末尾添加如下内容:
export NVM_DIR="$([ -z "${XDG_CONFIG_HOME-}" ] && printf %s "${HOME}/.nvm" || printf %s "${XDG_CONFIG_HOME}/nvm")"
[ -s "$NVM_DIR/nvm.sh" ] && \. "$NVM_DIR/nvm.sh" # This loads nvm
4、source ~/.zshrc使配置生效,然后进行测试
5、查看nvm安装位置
|
Windows命令:
|
Linux命令:
|
方式二:参考以下链接安装
mac:https://github.com/nvm-sh/nvm , 国内镜像仓库地址:https://gitee.com/mirrors/nvm
安装脚本:
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.3/install.sh | bash
# or
wget -qO- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.1/install.sh | bash
# 国内
curl -o- https://gitee.com/mirrors/nvm/raw/master/install.sh | bashwindows:https://github.com/coreybutler/nvm-windows(opens new window)
常见nvm命令(Mac):
|
包管理器npm&yarn&pnpm
介绍
npm:node默认的包管理工具(自带)
npm(node package manage)node 包 管理器,管理node包的工具。
包是什么?包就是模块,一个包可以包括一个或多个模块。
npm不需要额外的安装,只需要安装node,即会自动的安装npm。
yarn:特点扁平化依赖,并行安装,本地缓存
npm i -g yarn
# 这样才能国内加速安装
yarn config set registry https://registry.npmmirror.com
# yarn的命令与npm有出入
# 参考:http://www.imooc.com/wiki/yarnlessonpnpm:特点
- 节约磁盘空间,缓存技术加持
- 速度快
- 支持 monorepo
- 安全性高
npm i -g pnpm官方地址:https://pnpm.io/zh/motivation(opens new window)
核心:创建非扁平化的 node_modules 文件夹
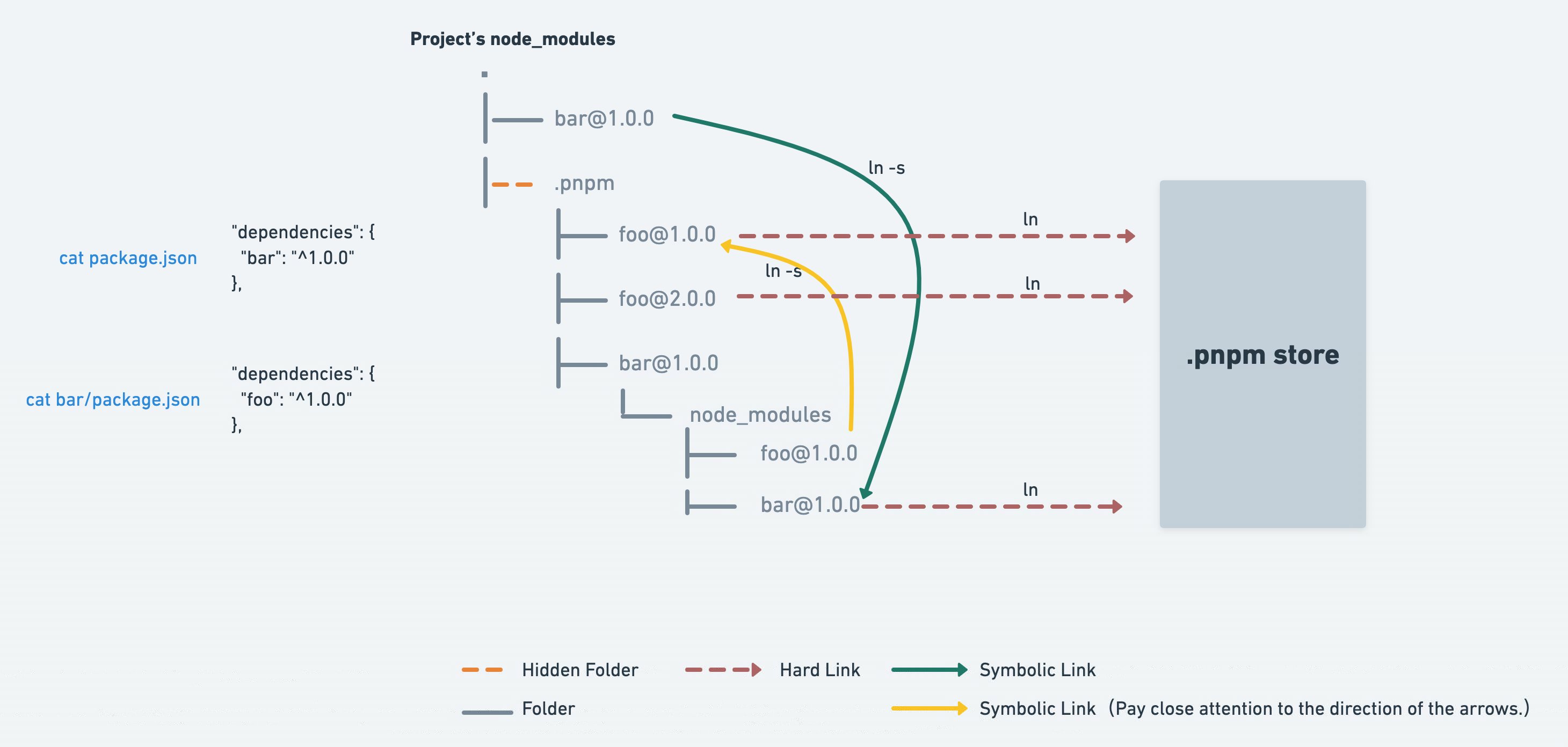
使用 npm 或 Yarn Classic 安装依赖项时,所有包都被提升到模块目录的根目录。 因此,项目可以访问到未被添加进当前项目的依赖。
默认情况下,pnpm 使用软链的方式将项目的直接依赖添加进模块文件夹的根目录。
如果你想了解 pnpm 关于
node_modules结构设计的更多细节,以及为什么它在 Node.js 生态成为了后起之秀,请参考:
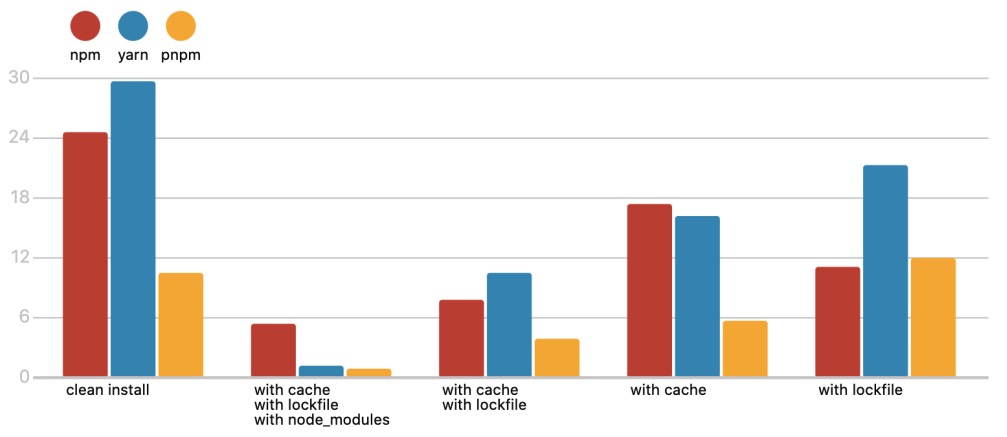
下载速度对比:
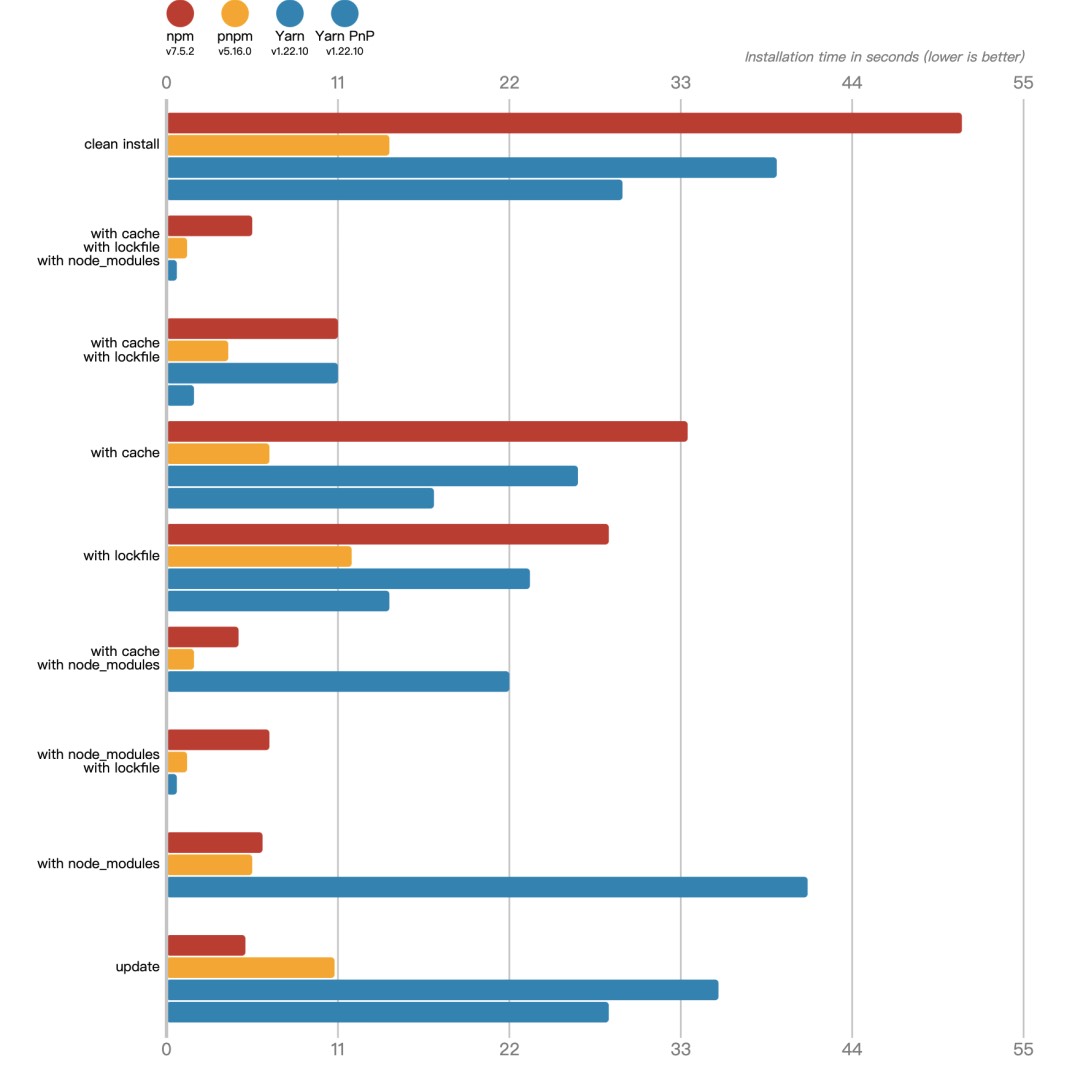
node12下,benchmark对比:
npm国内加速
初始化之后,就可以在当前文件夹中安装第三方模块了
|
常见命令
|
关于本地模块的说明
- 下载安装的模块,存放在当前文件夹的
node_modules文件夹中,同时还会生成一个记录下载的文件package-lock.json - 下载的模块,在哪里可以使用
- 在当前文件夹
- 在当前文件夹的子文件夹
- 在当前文件夹的子文件夹的子文件夹
- ……
- 翻过来讲,当查找一个模块的时候,会在当前文件夹的 node_modules 文件夹查找,如果找不到,则去上层文件夹的node_modules文件夹中查找,…..依次类推。
重要:代码文件夹不能有中文;代码文件夹不能和模块名同名。
NPM包管理工具
这个部分是扩展npm命令的篇章,主要应用场景:
- 版本号管理
- 发包
版本号管理

npm version命令是用来管理package.json中的version属性的。
相比于使用git tag命令,npm version = 修改package.json中的version + git tag打标签。
并且,npm version针对于语义化的版本号,设置了不同的命令:
预发布相关:
- prerelease
- prepatch
- preminor
- premajor
正式发布相关
- patch
- minor
- Major
预发布相关
npm version
这里主要是npm version命令的相关介绍。
|
直接使用npm version:
|
prerelease
pre-预
release-发布版
所以,prerelease就是预发版。
TIP
记住:release是最后面的号。
原则:
- 当执行
npm version prerelease时,如果没有预发布号,则增加minor,同时prerelease 设为0; - 如果有prerelease, 则prerelease 增加1。
|
prepatch
直接升级小号,增加预发布号为0。
TIP
因为跟pre预发布有关,所以会带个尾巴。
|
preminor
直接升级中号,小号置为0,增加预发布号为0。
|
premajor
直接升级大号,中号、小号置为0,增加预发布号为0。
|
正式版本相关
patch
TIP
记住:patch是小号。
原则:
- patch:如果有prerelease ,则去掉prerelease ,其他保持不变;
- 如果没有prerelease ,则升级minor,即是最小号。
|
minor
TIP
记住:minor是中间的号。
原则:
- 如果没有prerelease,直接升级minor, 同时patch设置为0;
- 如果有prerelease, 首先需要去掉prerelease;
- 如果patch为0,则不升级minor;
- 如果patch不为0, 则升级minor,同时patch设为0;
|
major
TIP
记住: major是主号,也是大号
|
主要目的升级major,原则:
- 如果没有premajor,则直接升级major,其他位都置为0;如果有premajor,则会去掉premajor版本号;
- 如果有preminor/prepatch/prerelease,则会去掉
release版本; - 如果有minor/patch,则会直接置0,升级主版本号;
发包相关
常见的npm publish、npm link、npm login这里不介绍了,主要介绍与发包之后的命令:
- 查看历史版本
- 删除版本
- 废弃版本
查看历史版本
言归正传,如何查看已发布包的历史版本呢?
使用命令:
|
一般来说,这个命令就已经够了,如果发布的版本有100个以上,可能下面的这个命令能用的上。
和上面的类似,只需在后面加上 --json 即可查看所有的历史版本。
|
如果想查看最新的版本呢?
|
注意细节哦,versions少了一个s 。
但是这个是针对正式版本的,如果是测试版本,是不会出现在最新版本的查询里的。
删除版本
删除版本前,一定要确认这个版本的包已经没有依赖(废弃)了。
|
废弃版本
什么是废弃版本?
就是npm包还在,但是受某些因素影响,该包不再维护,不再更新了。
简单来说,就是不影响使用,但是在安装废弃版本的时候会有提示。
|
Koa(下一代web框架)
koa (opens new window)(中文网 (opens new window))是基于 Node.js 平台的下一代 web 开发框架,致力于成为应用和 API 开发领域中的一个更小、更富有表现力、更健壮的基石;利用async 函数丢弃回调函数,并增强错误处理,koa 没有任何预置的中间件,可快速的编写服务端应用程序。
核心概念
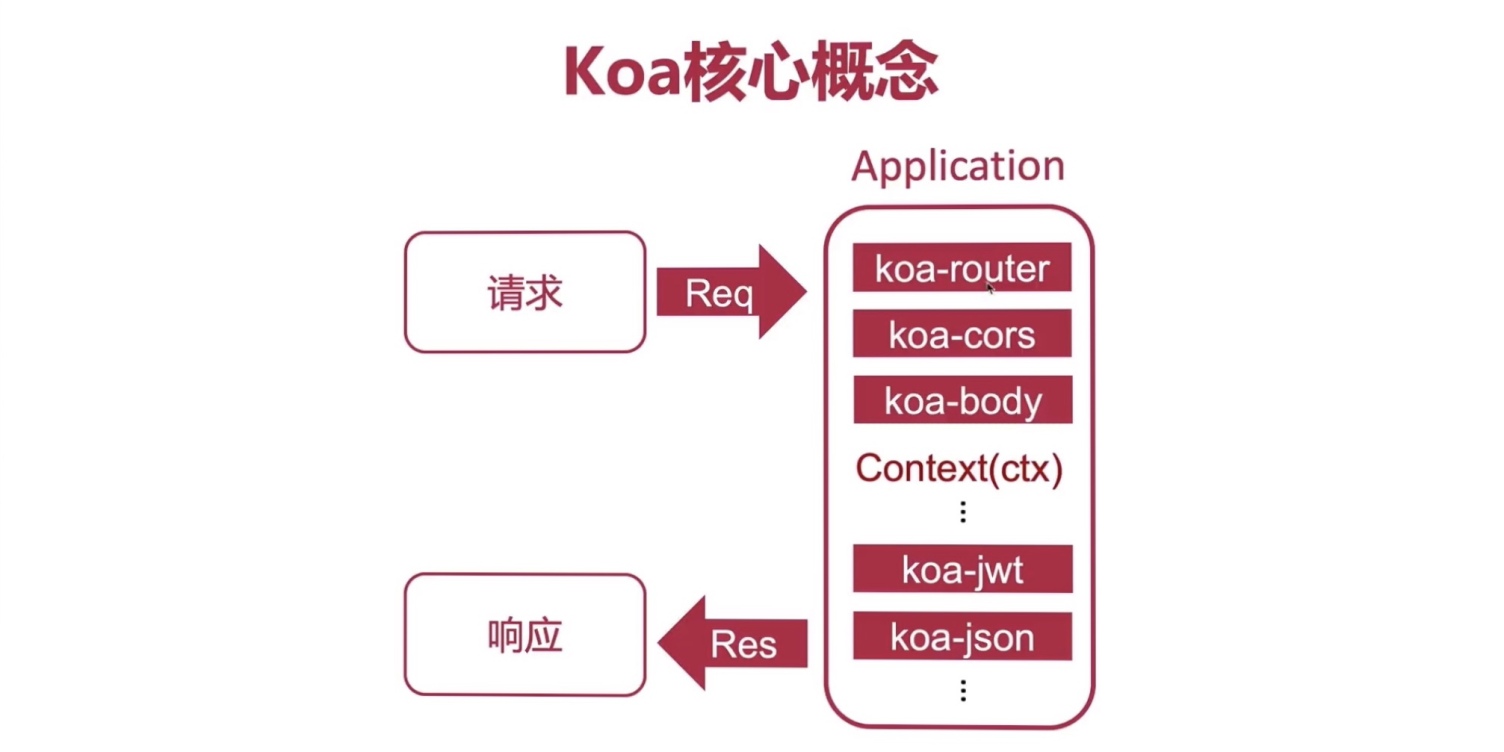
- Koa Application(应用程序)
- Context(上下文)
- Request(请求)、Response(响应)
初识 koa
|
TIP
可以在 package.json 中查看安装的所有依赖
在工程目录里创建一个 app.js,代码如下:
|
在终端中使用node app.js命令(前提是终端中的路径必须指向所创建工程文件夹的路径) 打开浏览器访问:http://localhost:3003 此时浏览器中就会输出hi koa,如下图:

WARNING
上面代码虽然轻松实现了一个 web 服务器,但是返回的数据和所请求都是固定的;并不适应真实的业务场景,比如:获取请求接口时的参数、方法、修改一次代码就要在终端中重新运行启动命令等;
由于使用的node app.js启动,所以每次更改都要重新启动,这样给我们开发带来了极大的不便利,所以我们可以使用一些第三方依赖来自动监听文件的变化并重新启动,开发环境可以使用nodemon 首先安装npm i nodemon -D,也可以全局安装此依赖,生产环境的话可以使用pm2 安装之后在package.json的scripts中添加启动方式;如下
|
在终端中执行命令:npm run dev,这样就不用我们每次修改都重新启动,执行之后就会在终端中提示,如下: 
TIP
执行命令时,终端的路径必须指向当前程序
路由
路由即是路径与处理函数之间的对应关系!
Koa中的路由作用:
- 处理不同的
URL - 处理不同的
HTTP方法 (GET、POST、PUT、DELETE、PATCH、OPTIONS) - 解析
URL上的参数
于 HTTP 协议而言,路由可以理解为,根据不同的 HTTP 请求,返回不同的响应;
使用方法:
- 安装依赖:
@koa/router - 定义路由
- 实例化
@koa/router - 注册router
- 定义接口
- 实例化
|
- 定义路由
- 在 app.js 中引入
@koa/router,然后再实例化
|
- 注册 router
|
- 定义接口
|
完整代码如下:
|
在浏览器中请求:http://localhost:3003/api/v1、http://localhost:3003/api/v1/user,结果如下图:

中间件
中间件其实就是一个个函数,中间件是一系列的中间过程执行的函数,它可以通过app.use()注册;
- 在 koa 中只会自动执行第一个中间件,后面的都需要我们自己调用。
- koa 在执行中间件的时候都会携带两个参数
context(可简化为ctx)和next,其中:context是 koa 的上下文对象next就是下一个中间件函数,也就是洋葱模型;
所谓洋葱模型,就是指每一个 Koa 中间件都是一层洋葱圈,它即可以掌管请求进入,也可以掌管响应返回。
换句话说:外层的中间件可以影响内层的请求和响应阶段,内层的中间件只能影响外层的响应阶段。

执行顺序按照 app.use()的顺序执行,中间件可以通过 await next()来执行下一个中间件,同时在最后一个中间件执行完成后,依然有恢复执行的能力。即,通过洋葱模型,await next()控制调用 “下游”中间件,直到 “下游”没有中间件且堆栈执行完毕,最终流回“上游”中间件。
下面这段代码的结果就能很好的诠释,示例:
|
运行结果:
|
原理:中间件是如何执行的?
|
Koa 框架通过 http 模块的 createServer 方法创建一个 Node.js 服务,并传入 this.callback() 方法, this.callback() 方法源码精简实现如下:
|
将 Koa 一个中间件组合和执行流程梳理为以下步骤:
- 通过 compose 方法组合各种中间件,返回一个中间件组合函数 fnMiddleware
- 请求过来时,会先调用 handleRequest 方法,该方法完成:
- 调用 createContext 方法,对该次请求封装出一个 ctx 对象;
- 接着调用 this.handleRequest(ctx, fnMiddleware)处理该次请求。
- 通过 fnMiddleware(ctx).then(handleResponse).catch(onerror)执行中间件。
传参(取参)方式
- 在 params 中取值,
eg:http://localhost:3003/api/v1/user/1
|
- 在 query 中取值,也就是获取问号后面的。
|
- 获取 header 中的参数:
|
- 获取 body 中的数据,在服务端获取 body 中的一些数据只能用一些外部的插件;如:
koa-body、koa-bodyparser等等。 就以koa-body为例,首先安装npm i koa-body -S,再引入:
|
创建 RESTful 接口
- 路由 koa-router
- 协议解析 koa-body
- 跨域处理 @koa/cors
- JSON美化 koa-json
koa的设计思想就是将数据处理都交给中间件:
|
案例:
|
TIP
koa-body 中间件的引入顺序必须在 router 之前,否则获取不了 post 请求携带的数据
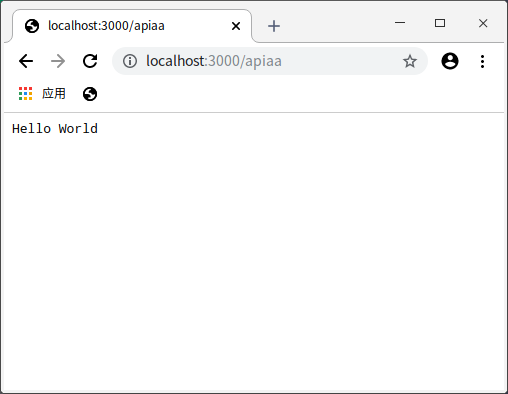
params传参:
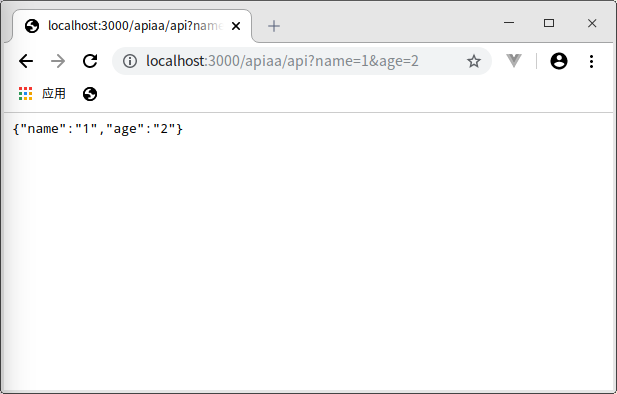
POST传参:
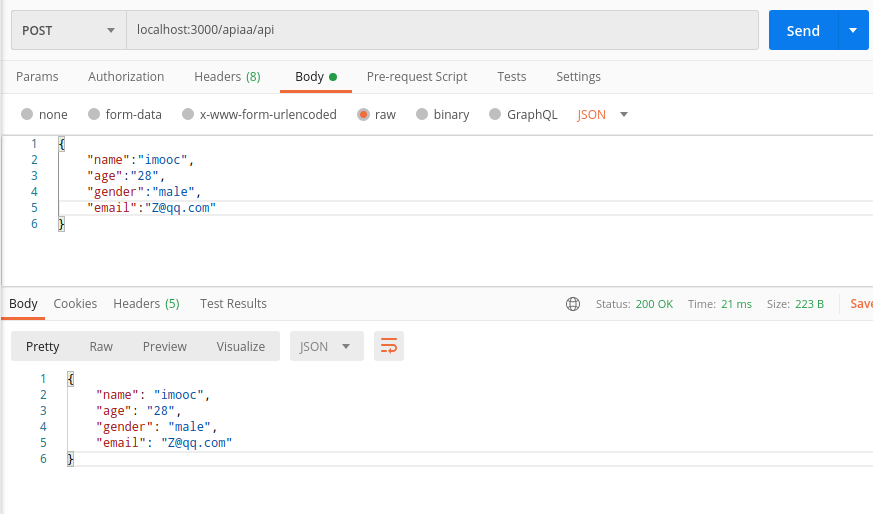
小案例
任务描述:
通过header里面传递一个role属性admin,使用post请求,发送给koa这边的/api/user接口json数据为{name: “imooc”, email: ["imooc@test.com](mailto:"imooc@test.com)"}。
具体返回格式与要求如下:
POSTMan中发送请求
情景一:无name或者email
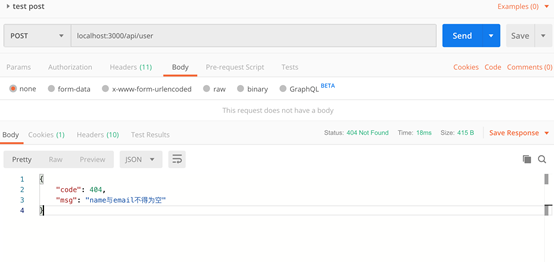 **
**
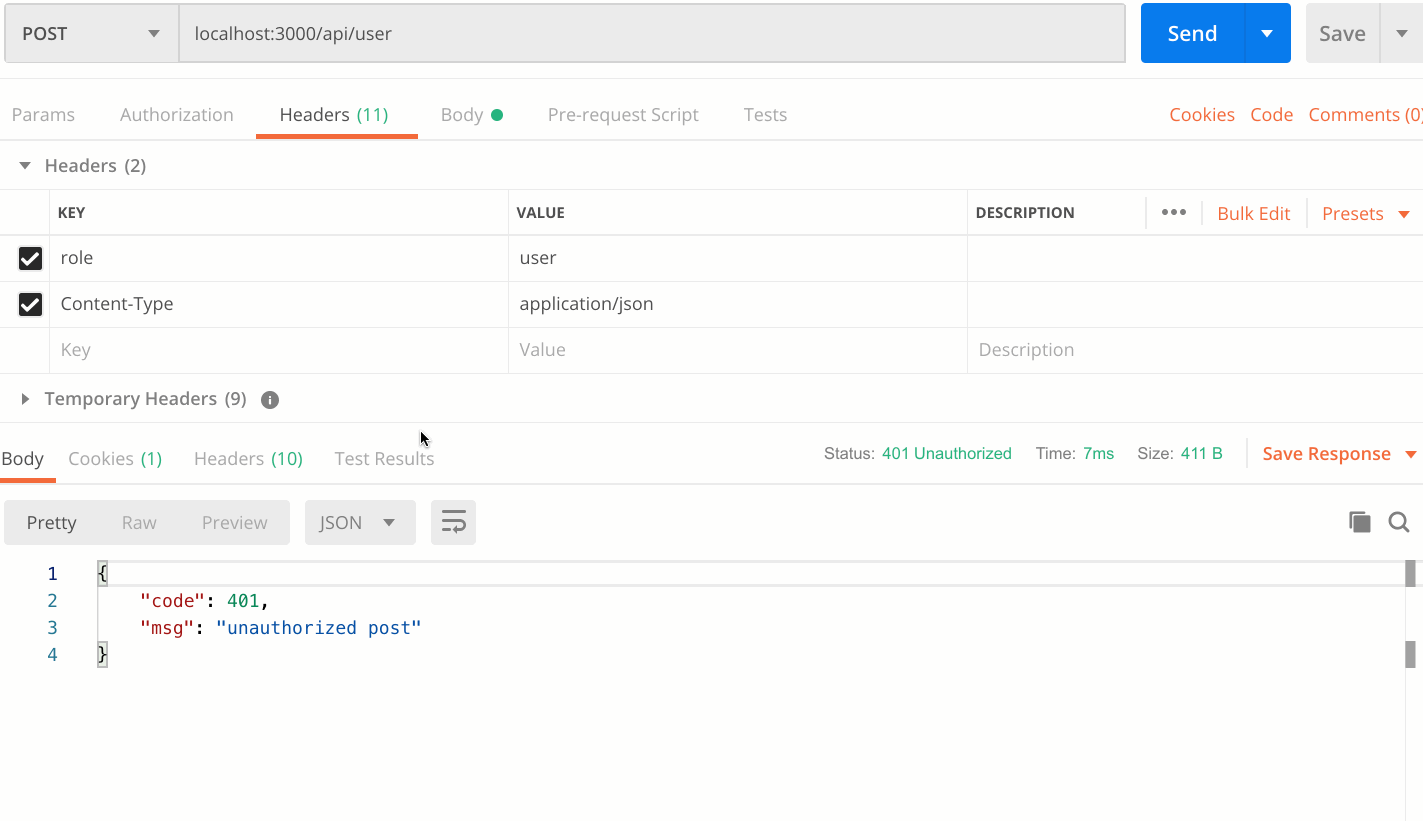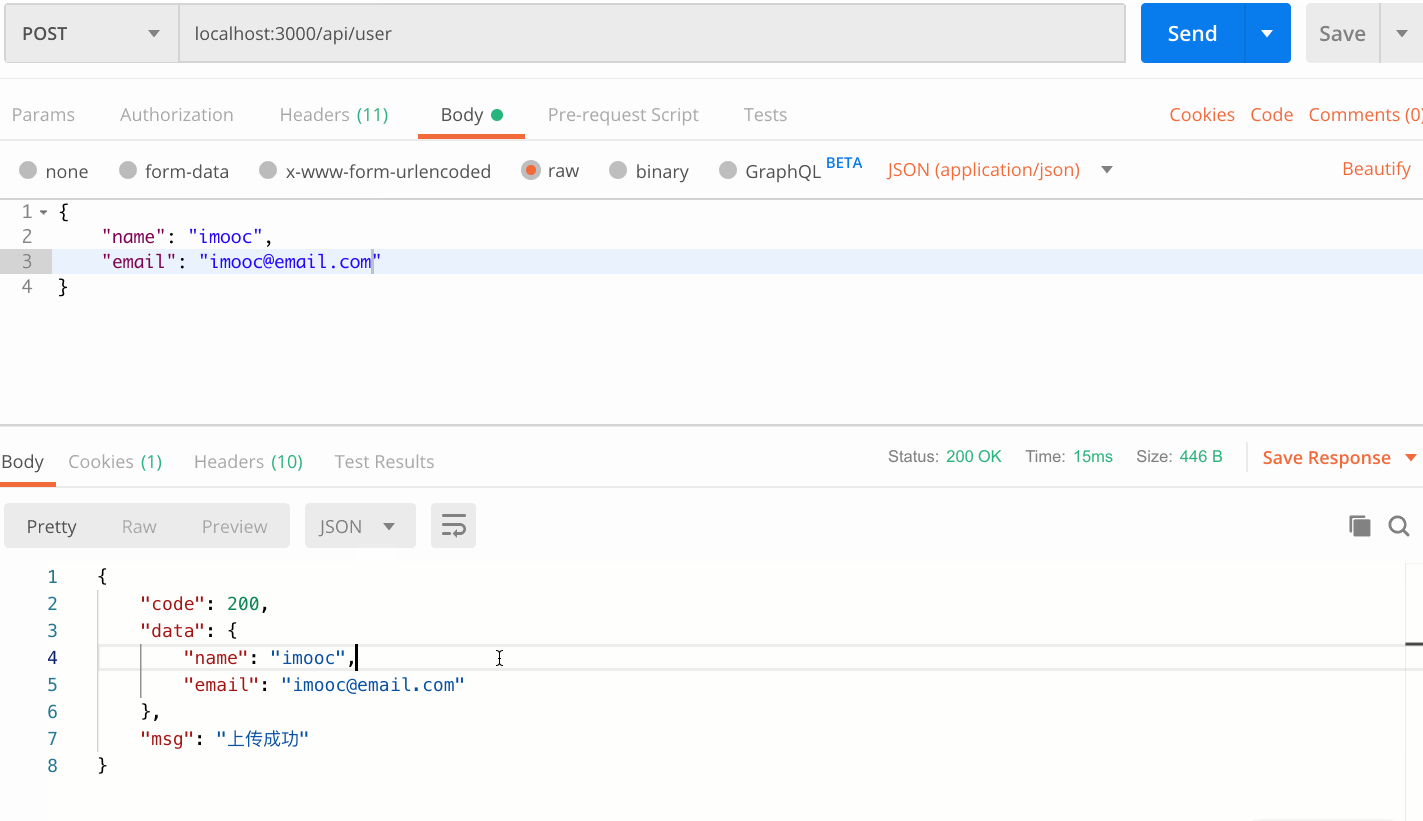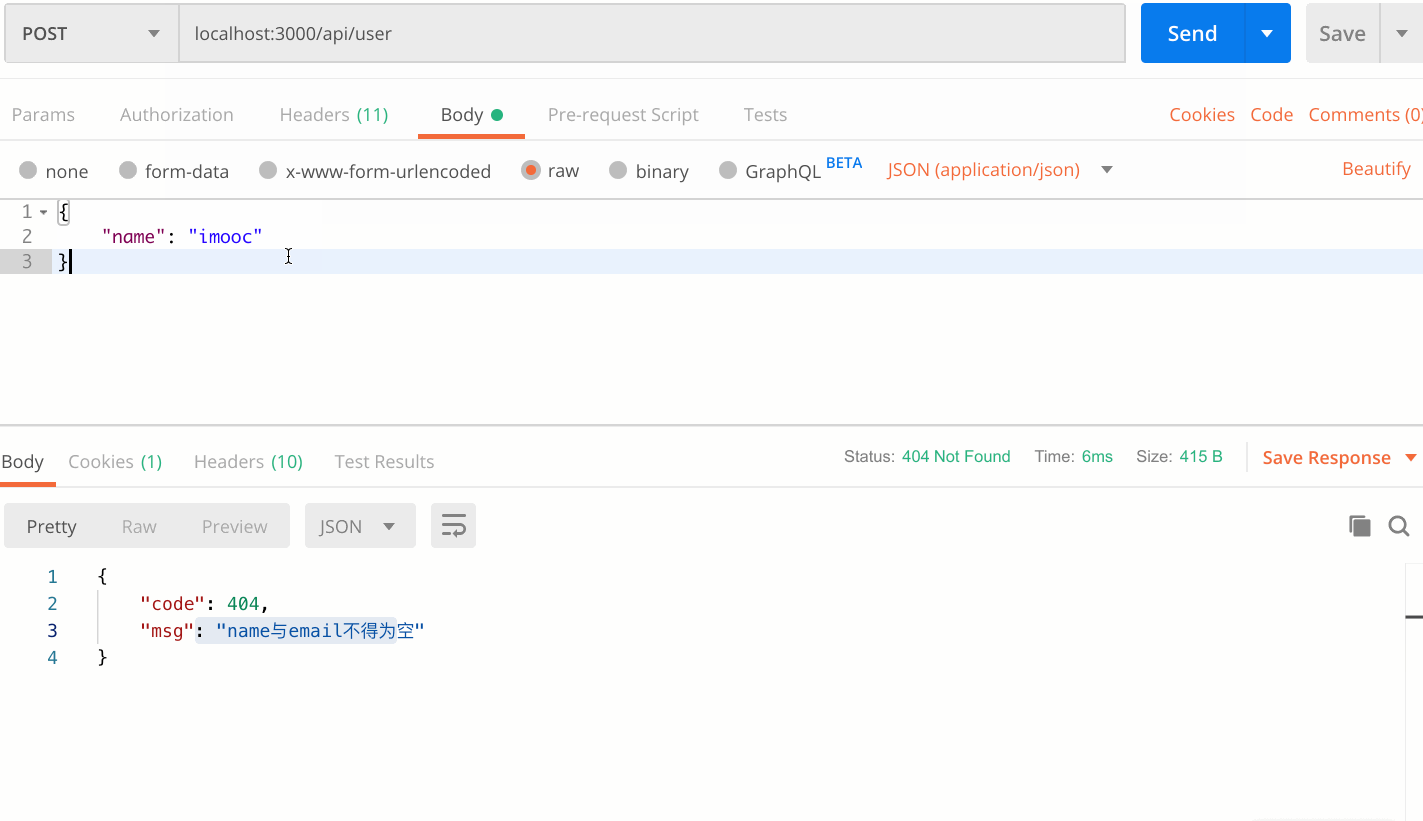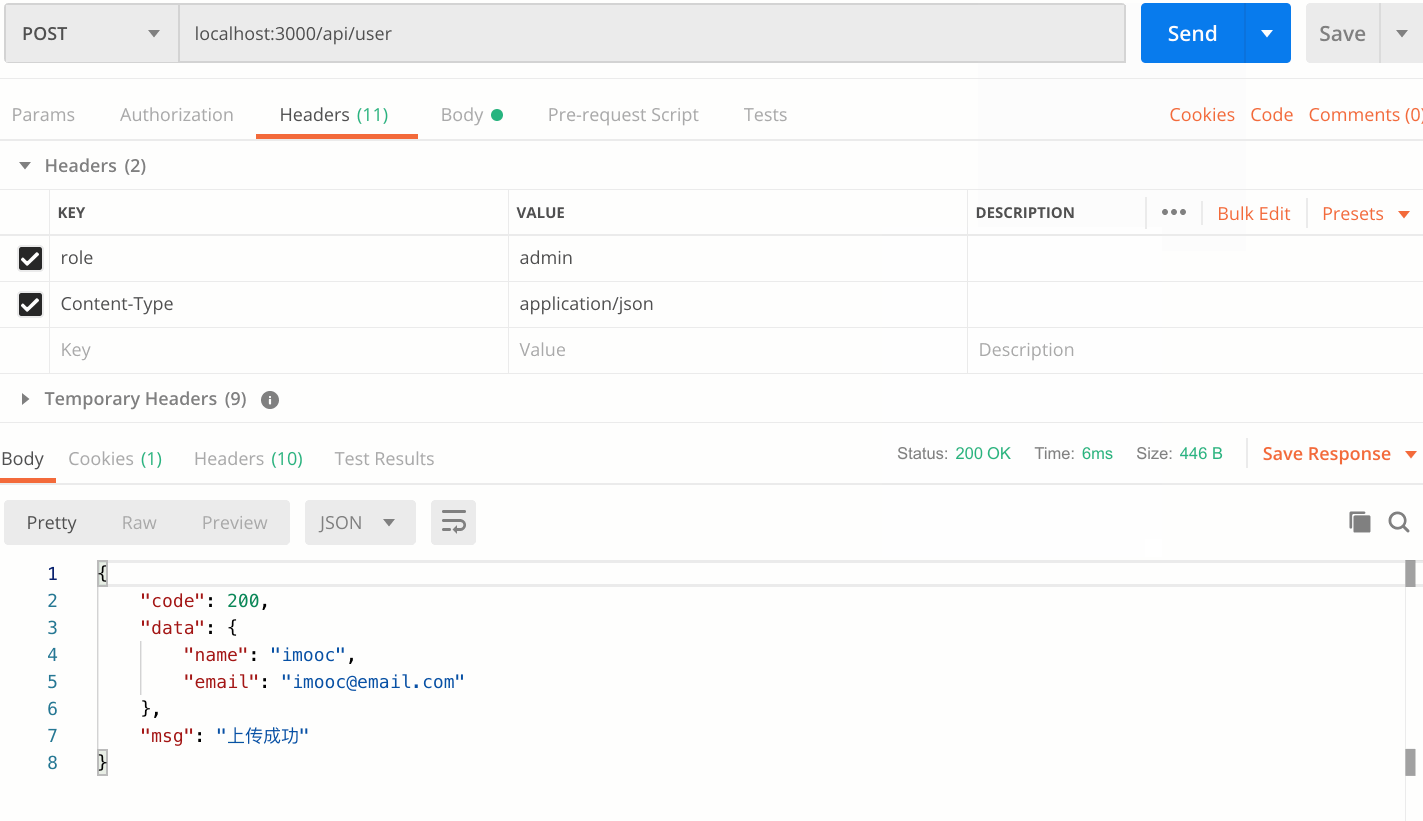
情景二:Header中无admin或者role不等于admin
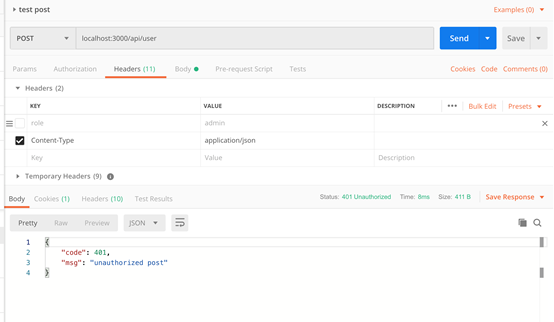
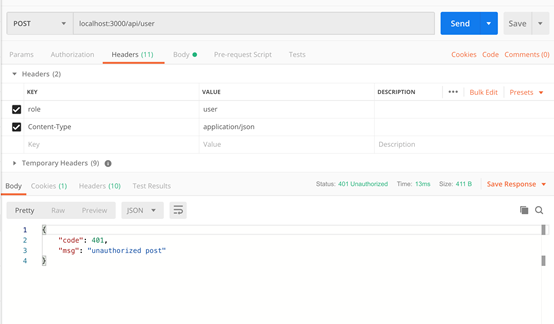
情景三:正常请求
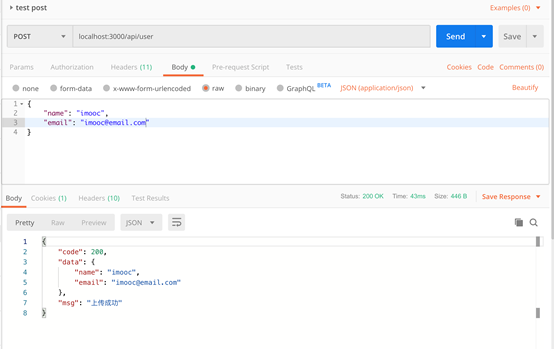
效果图展示如下:
 任务要求:
任务要求:
- koa侧判断role属性是否存在,是否是admin,不是,则返回status 401
- 判断email与name属性是否存在,并且不为空字符串
- 返回用户上传的数据,封装到data对象中,给一个code: 200,message: ‘上传成功’。
package.json:
|
app.js
|
#webpack5构建加持
更多webpack相关的内容,可以翻看webpack的专栏。
#项目目标
- 支持 es6+语法
- 开发热更新
- webpack5 构建
- 接口搭建
- 路由合并,路由自动注册
- 添加项目规范
- 配置自定义别名
#项目目录结构
|
#搭建项目
|
- 安装
koa、@koa/router(如果已经配置可路过)
|
- 创建入口文件
|
- 安装构建依赖
|
- 在项目根目录添加
.babelrc文件
|
- 添加测试接口
在
app.js中添加测试接口,由于已经配置了babel解析,所以可以直接在app.js中写 es6+语法
|
- 启动服务
|
- 在 postman 中请求接口

#配置 webpack
核心概念
- entry:入口;指示
webpack应该使用哪个模块,默认值是./src/index.js - output:输出;
output属性告诉webpack在哪里输出它所创建的 bundle,默认值是./dist/main.js - loader:loader 负责完成项目中各种各样资源模块的加载
- plugins:插件;用来解决项目中除了资源模块打包以外的其他自动化工作。包括:打包优化,资源管理,注入环境变量
- mode:模式;通过选择
development,production或none之中的一个,来设置mode参数,你可以启用 webpack 内置在相应环境下的优化。其默认值为production。
在项目根目录创建
webpack.config.js文件
|
#测试构建
|


构建成功!
思考
在实际开发中可能会存在开发环境和生产环境的构建,所以单凭一个配置还不能达到实际的需求,接下来对开发环境和生产环境分别配置。
在项目根目录创建 config 文件,并创建三个文件分别是
webpack.config.base.js、webpack.config.dev.js、webpack.config.prod.js
webpack.config.base.js文件存放开发环境和生产环境都是需要的构建配置webpack.config.dev.js文件存放开发环境的构建配置webpack.config.prod.js存放生产环境的构建配置
#优化构建配置
- mode 独立于构建环境,开发环境为(
development)、生产环境为(production)- devtool 只有在开发环境下才会存在
- stats (opens new window)属性让你更精确地控制打包后的信息该怎么显示
TIP
由于每个开发环境和生产环境都是独立的构建配置,所以要在构建时要合并基础配置;安装webpack-merge合并构建配置
|
- 优化 webpack.config.base.js
|
- 开发环境的构建配置
|
- 生产环境的构建配置
生产环境构建时要进行代码压缩,安装
terser-webpack-plugin, 命令:npm i -D terser-webpack-plugin
|
添加构建脚本命令
设置环境变量
NODE_ENV,由于各环境配置的差异问题,cross-env可以有效的解决跨平台设置环境变量的问题;它是运行跨平台设置和使用环境变量(Node 中的环境变量)的脚本。安装命令:npm i -D cross-env安装成功后配置构建命令:- 在
package.json的scripts中添加如下命令:
"build": "cross-env NODE_ENV=prod webpack --config config/webpack.config.prod.js",
"dev": "cross-env NODE_ENV=dev nodemon --exec babel-node --inspect src/app.js",- 在
启动开发环境服务
|
运行之后的效果图如下:
- 启动编译构建命令
|
运行效果如下图:

查看 dist 文件夹下被编译后的文件:
被压缩成了一整行!
#路由自动注册
#使用require-directory
在 src 文件夹下新建 routes 和 api 两文件夹;routes 是集成当前项目的所有路由,api 文件是存放项目的所有接口文件。
安装
require-directory(opens new window),这个包的作用可以将一个目录下的所有模块文件$ npm i require-dirctory创建
src/api/v1下创建demo.js和test.js文件// src/api/v1/demo.js
import Router from '@koa/router'
const router = new Router({ prefix: '/api/v1' })
router.get('/demo', async ctx => {
ctx.body = {
status: 200,
message: 'message',
data: {
file: 'demo.js',
title: 'webpack 5 构建node应用',
content: 'koa + @koa/router + require-dirctory'
}
}
})
export default router// src/api/v1/test.js
import Router from '@koa/router'
const router = new Router({ prefix: '/api/v1' })
router.get('/test', async ctx => {
ctx.body = {
status: 200,
message: 'message',
data: {
file: 'test.js',
title: 'webpack 5 构建node应用',
content: 'koa + @koa/router + require-dirctory'
}
}
})
export default router配置
src/routes/index.jsimport Router from '@koa/router'
import requireDirectory from 'require-directory'
// 接口存放目录路径
const apiDirectory = `${process.cwd()}/src/api`
function initLoadRoutes(app) {
requireDirectory(module, apiDirectory, {
visit({ default: router }) {
if (router instanceof Router) {
app.use(router.routes())
}
}
})
}
export default initLoadRoutes修改
src/app.js文件import Koa from 'koa'
import initLoadRoutes from './routes/index'
const app = new Koa()
// 在入口文件中执行
initLoadRoutes(app)
const port = 3002
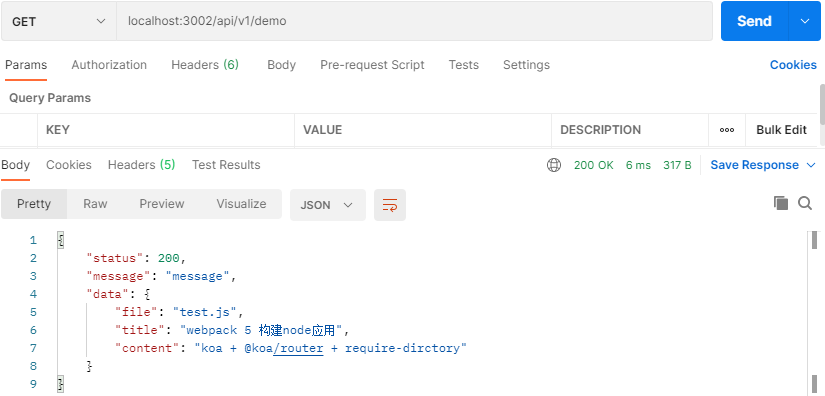
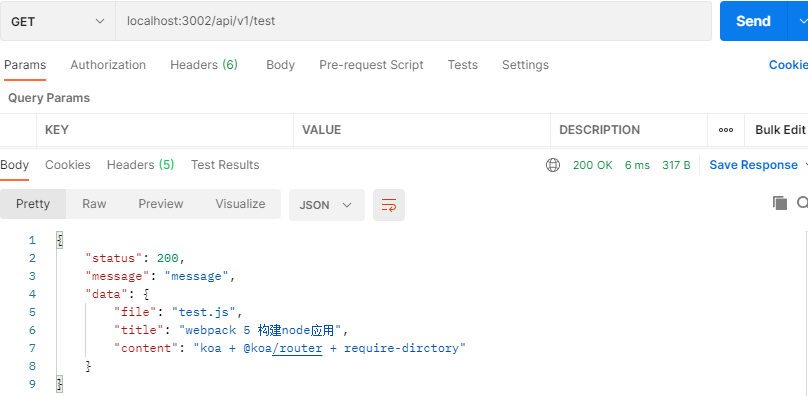
app.listen(port, () => console.log(`服务启动在${port}端口`))在 postman 中测试请求如下图

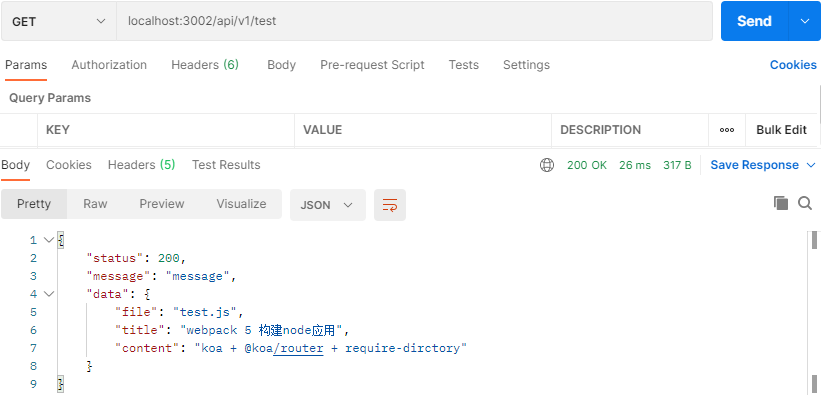
到此自动注册路由就大功告成了,后面我们定义接口的时候就用手动一个一个的引入,只管往 api 文件夹里写接口就好了。
#使用require.context(webpack)功能
官方文档:require(opens new window)
举例:
|
目标:使用routes.js来动态加载modules目录中的.js的路由文件,其他的比如:vuex、vue-router等场景,都适合。
先上实现出来的代码:
routes.js文件
|
使用方法,在index.js入口文件中:
|
这里有两个知识点:
使用
koa-combine-routers可以合并多个路由使用
require.context可以动态引入多个文件
说明:
require.context返回的是一个函数
这个函数的键值,正是文件
moduleFiles.keys()
(14) ['./adminRouter.js', './commentsRouter.js', './contentRouter.js', './loginRouter.js', './publicRouter.js', './userRouter.js', './wxRouter.js', 'routes/modules/adminRouter.js', 'routes/modules/commentsRouter.js', 'routes/modules/contentRouter.js', 'routes/modules/loginRouter.js', 'routes/modules/publicRouter.js', 'routes/modules/userRouter.js', 'routes/modules/wxRouter.js']这个函数接收文件名后,可以返回文件的内容,这个内容正好匹配路由,输出一个数组,传递给conbineRoutes方法,即可合并。
const value = moduleFiles(path)
#配置别名
在日常开发中我们引入一些封装好的方法或者模块总是写很长很长的文件路径;比如:require('../../../../some/very/deep/module')、import format from '../../../../utils/format',为了告别这种又臭又长的路径我们就可以使用一些解放生产力的方法了(哈哈哈哈,不会偷懒的程序员不是好程序员 🤭)
配置别名有两种方式,一种是 webpack,另一种是通过module-alias (opens new window)包
#使用webpack的别名功能
官方文档: resolve.alias(opens new window)
配置方式,非常的简单方便:
|
#使用module-alias
安装依赖
npm i module-alias在
package.json中添加自定义别名"_moduleAliases": {
"@": "./src",
"@controller": "./src/controller"
}
在入口文件的顶部引入
module-alias/register,也就是在app.js的顶部引入require('module-alias/register')
配置成功后,将
/src/api/v1内的逻辑全部提到src/controller中,使用别名引入controller中文件,修改后如下:
|
postman 中测试接口
commit 时 lint-staged 没有通过:
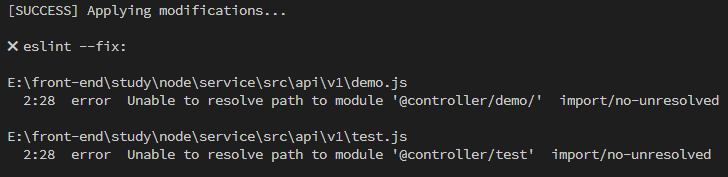
上述问题是 eslint 发现
@controller/*开头的在 node_modules 中没有找到,所以配置 eslint 就好了:
// src/eslintrc.js
module.exports = {
//...
rules: {
'import/no-unresolved': [2, { ignore: ['^@/', '@controller'] }] // @和@controller 是设置的路径别名
}
}

这个问题是由于
constructor构造函数为空引起的,在eslintrc.js添加配置即可:’no-empty-function’: [‘error’, { allow: [‘constructors’] }]
完整代码见:GitHub(opens new window)
#项目规范及工具
#集成 EditorConfig
EditorConfig (opens new window)有助于为不同 IDE 编辑器上处理同一项目的多个开发人员维护一致的编码风格。
在项目根目录下增加 .editorconfig 文件, 并配置以下内容:
|
注意
VSCode 使用 EditorConfig 需要去插件市场下载插件 EditorConfig for VS Code 。WebStorm 则不需要安装,直接使用 EditorConfig 配置即可。
#集成 Prettier
Prettier (opens new window)是一款强大的代码格式化工具,支持
JavaScript、TypeScript、CSS、SCSS、Less、JSX、Angular、Vue、GraphQL、JSON、Markdown等语言,基本上前端能用到的文件格式它都可以搞定,是当下最流行的代码格式化工具。
- 安装 Prettier
|
- 创建 Prettier 配置文件 Prettier 支持多种格式的配置文件,比如
.json、.yml、.yaml、.js等。 在本项目根目录下创建.prettierrc文件。 - 配置
.prettierrc在本项目中,进行如下简单配置,关于更多配置项信息,请前往官网查看 Prettier-Options (opens new window)。
|
Prettier 安装且配置好之后,就能使用命令来格式化代码
- 格式化所有文件(. 表示所有文件)
|
注意
VSCode 编辑器使用 Prettier 配置需要下载插件 Prettier - Code formatter; WebStorm 则不需要安装,直接使用 EditorConfig 配置即可。
#集成 ESLint
ESLint (opens new window)是一款用于查找并报告代码中问题的工具,并且支持部分问题自动修复。其核心是通过对代码解析得到的 AST(Abstract Syntax Tree 抽象语法树)进行模式匹配,来分析代码达到检查代码质量和风格问题的能力。 使用 ESLint 可以尽可能的避免团队成员之间编程能力和编码习惯不同所造成的代码质量问题,一边写代码一边查找问题,如果发现错误,就给出规则提示,并且自动修复,长期下去,可以促使团队成员往同一种编码风格靠拢。
- 安装 eslint
|
配置 ESLint
ESLint 安装成功后,执行
npx eslint --init,然后按照终端操作提示完成一系列设置来创建配置文件。
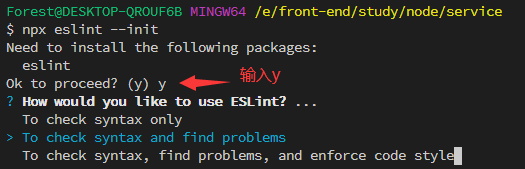
How would you like to use ESLint? …(你想如何使用 ESLint?…)
我这里选择第三个,检查语法,发现问题,并强制代码样式

What type of modules does your project use? … (你的项目使用什么类型的模块?…)
项目支持 es6+语法,所以这里就直接选用第一项:JavaScript modules (import/export)
Which framework does your project use? … (你的项目使用哪种框架?…)
这里并未使用 vue 和 react,所以选择 none of these

Does your project use TypeScript? (你的项目使用 TypeScript 吗?)
项目中并没有使用 Typescript,所以选择 No
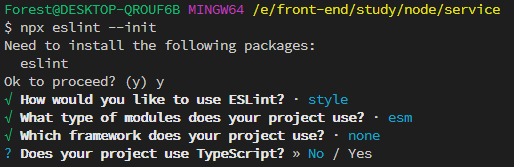
Where does your code run?(你的代码在哪里运行?)
这是 node 项目,所以不需要选择浏览器环境

How would you like to define a style for your project? … (你想怎样为你的项目定义风格?)
这里选择 Use a popular style guide(使用一种流行的风格指南)
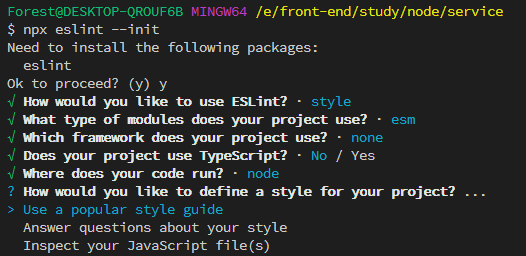
Which style guide do you want to follow? … (你想遵循哪种风格指南?…)

What format do you want your config file to be in? … (您希望配置文件的格式是什么?…)
我这里选择 JavaScript
Would you like to install them now with npm?(你想现在用 npm 安装它们吗?)
默认 Yes,所以可以直接回车

所有配置如下
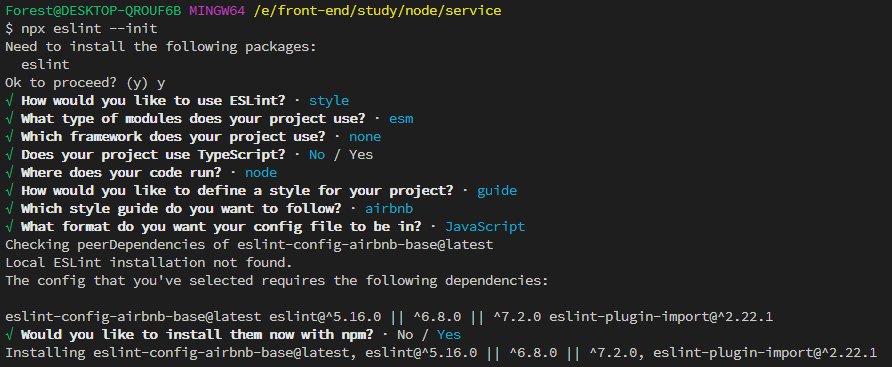
安装成功后,项目的根目录就会多一个.eslintrc.js文件,其中的内容就是在终端中选择的相应配置。
注意
VSCode 使用 ESLint 配置文件需要去插件市场下载插件 ESLint 。 
#Webpack 中使用 ESLint(不推荐)
首先需要安装eslint-loader:
|
然后在 webpack.config.js 中module.rules添加如下代码:
|
- ESLint 的配置单独做了一个 Webpack 的
module.rule配置,所以使用了enforce: 'pre'来调整了 loader 加载顺序,保证先检测代码风格,之后再做 Babel 转换等工作; - 也可以放到 Babel 放到一起,不过要将
eslint-loader放到babel-loader之前检测; - 这里为了让 ESLint 报错更加好看一些,使用了eslint-formatter-friendly (opens new window)这个 ESLint
formatter,记得安装它:npm i -D eslint-formatter-friendly
新建一个 entry 文件,内容如下:
|
不推荐理由:使用lint-stage 结合 husky就可以做eslint的代码检查与优化了
#Webpack 中使用 StyleLint(不推荐)
Webpack 中使用 StyleLint 是通过插件的方式来使用,这个插件的名字是 stylelint-webpack-plugin (opens new window)。
|
安装之后,按照插件的使用方式在 webpack.config.js 添加配置:
|
默认 StyleLint-webpack-plugin 会查找项目中的 StyleLint 配置文件,根据配置文件的配置来检测 CSS 代码。
在 stylelint-webpack-plugin 插件中有两个跟 Webpack 编译相关的配置项:
emitErrors:默认是true,将遇见的错误信息发送给 webpack 的编辑器处理;failOnError:默认是false,如果是true遇见 StyleLint 报错则终止 Webpack 编译。
#解决 Prettier 和 ESLint 的冲突
本项目中的 ESLint 配置中使用了 Airbnb JavaScript 风格指南校验,其规则之一是代码结束后面要加分号,而在 Prettier 配置文件中加了代码结束后面不加分号的配置项,这样就有冲突了,会出现用 Prettier 格式化后的代码,ESLint 检测到格式有问题的,从而抛出错误提示。 解决两者冲突问题,需要用到 eslint-plugin-prettier 和 eslint-config-prettier。
eslint-plugin-prettier将 Prettier 的规则设置到 ESLint 的规则中。
eslint-config-prettier关闭 ESLint 中与 Prettier 中会发生冲突的规则。
最后形成优先级:Prettier 配置规则 > ESLint 配置规则。
- 安装插件
|
- 在
.eslintrc.js添加 prettier 插件
|
这样,在执行 eslint --fix 命令时,ESLint 就会按照 Prettier 的配置规则来格式化代码,轻松解决二者冲突问题。
#集成 husky 和 lint-staged
在项目中已集成 ESLint 和 Prettier,在编码时,这些工具可以对写的代码进行实时校验,在一定程度上能有效规范写的代码,但团队可能会有些人觉得这些条条框框的限制很麻烦,选择视“提示”而不见,依旧按自己的一套风格来写代码,或者干脆禁用掉这些工具,开发完成就直接把代码提交到了仓库,日积月累,ESLint 也就形同虚设。 所以,还需要做一些限制,让没通过 ESLint 检测和修复的代码禁止提交,从而保证仓库代码都是符合规范的。 为了解决这个问题,需要用到 Git Hook,在本地执行 git commit 的时候,就对所提交的代码进行 ESLint 检测和修复(即执行 eslint --fix),如果这些代码没通过 ESLint 规则校验,则禁止提交。 实现这一功能,借助 husky + lint-staged 。
husky —— Git Hook 工具,可以设置在 git 各个阶段(pre-commit、commit-msg、pre-push 等)触发的命令。 lint-staged —— 在 git 暂存的文件上运行 linters。
#配置 husky
TIP
使用 husky-init 命令快速在项目初始化一个 husky 配置。在配置 husky 之前必须初始化 git,否则可能会配置不成功
|
命令执行会经历以下四步流程:
安装
husky为开发依赖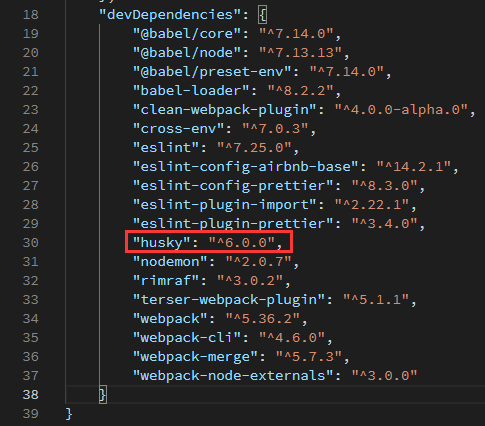
创建
.husky文件夹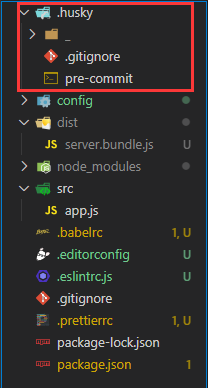
在
.husky目录创建pre-commithook,并初始化pre-commit命令为npm test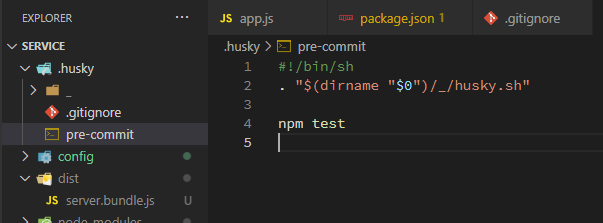
修改
package.json的scripts,增加"prepare": "husky install"
#配置 lint-staged
lint-staged 这个工具一般结合 husky 来使用,它可以让 husky 的 hook 触发的命令只作用于 git add那些文件(即 git 暂存区的文件),而不会影响到其他文件。
接下来,使用 lint-staged 继续优化项目。
安装 lint-staged
$ npm i lint-staged -D在
package.json里增加 lint-staged 配置项"lint-staged": {
"*.{vue,js,ts}": "eslint --fix"
},
修改
.husky/pre-commit hook的触发命令为:npx lint-staged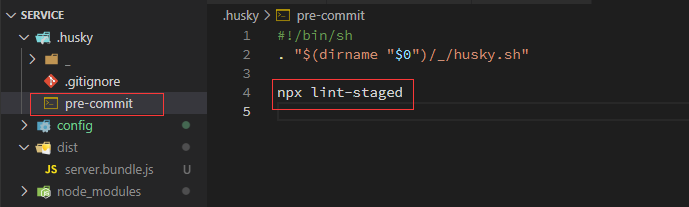
至此,husky 和 lint-staged 组合配置完成。
#集成stylelint
检测 CSS 语法使用StyleLint (opens new window)。
StyleLint 和 ESLint 很像,它们都只是提供了工具与规则,如何配置这些规则完全取决于使用者,所以要根据需要自己引入或配置规则。StyleLint 的代码风格也有很多社区开源版本,官方推荐的代码风格有两个:
要使用 StyleLint 需要先安装它:
|
除了 StyleLint 本身之外,还可以安装stylelint-order 插件 (opens new window),该插件的作用是强制在写 CSS 的时候按照某个顺序来编写。
例如先写定位,再写盒模型,再写内容区样式,最后写 CSS3 相关属性。这样可以极大的保证代码的可读性和风格统一。
StyleLint 的配置文件是.stylelintrc.json,其中的写法跟 ESLint 的配置类似,都是包含extend和rules等内容,下面是一个示例:
|
配置文件中单独配置 at-rule-no-unknown 是为了让 StyleLint 支持 SCSS 语法中的 mixin、extend、content 语法,更多详细的规则,可以查看官方文档 (opens new window)。
如何在webpack中使用stylelint,可以参考专栏文章:资源处理
#正则表达式入门
#目录
#入门
除了作为入门教程之外,本文还试图成为可以在日常工作中使用的正则表达式语法参考手册。
本文介绍的大部分正则语法,在不同的正则表达式引擎中都可以使用,但也有一些会有所差异。
#正则表达式是什么?
在编写处理字符串的程序或网页时,经常会有查找符合某些复杂规则的字符串的需要。正则表达式就是用于描述这些规则的工具。换句话说,正则表达式就是记录文本规则的代码。
很可能你使用过Windows/Dos下用于文件查找的通配符(wildcard),也就是和?。如果你想查找某个目录下的所有的Word文档的话,你会搜索.doc。在这里,会被解释成任意的字符串。和通配符类似,正则表达式也是用来进行文本匹配的工具,只不过比起通配符,它能更精确地描述你的需求——当然,代价就是更复杂——比如你可以编写一个正则表达式,用来查找所有以0开头,后面跟着2-3个数字,然后是一个连字号“-”,最后是7或8位数字的字符串(像010-12345678或0376-7654321*)。
字符是计算机软件处理文字时最基本的单位,可能是字母,数字,标点符号,空格,换行符,汉字等等。字符串是0个或更多个字符的序列。文本也就是文字,字符串。说某个字符串匹配某个正则表达式,通常是指这个字符串里有一部分(或几部分分别)能满足表达式给出的条件。
#如何学习正则表达式?
学习正则表达式的最好方法是从例子开始,理解例子之后再自己对例子进行修改,实验。
下面给出了不少简单的例子,并对它们作了详细的说明。
假设你在一篇英文小说里查找hi,你可以使用正则表达式hi。
这几乎是最简单的正则表达式了,它可以精确匹配这样的字符串:由两个字符组成,前一个字符是h,后一个是i。通常,处理正则表达式的工具会提供一个忽略大小写的选项,如果选中了这个选项,它可以匹配hi,HI,Hi,hI这四种情况中的任意一种。
不幸的是,很多单词里包含hi这两个连续的字符,比如him,history,high等等。用hi来查找的话,这里边的hi也会被找出来。如果要精确地查找hi这个单词的话,我们应该使用\bhi\b。
\b是正则表达式规定的一个特殊代码(好吧,某些人叫它元字符,metacharacter),代表着单词的开头或结尾,也就是单词的分界处。虽然通常英文的单词是由空格,标点符号或者换行来分隔的,但是\b并不匹配这些单词分隔字符中的任何一个,它只匹配一个位置。
如果需要更精确的说法,
\b匹配这样的位置:它的前一个字符和后一个字符不全是(一个是,一个不是或不存在)\w。
假如你要找的是hi后面不远处跟着一个Lucy,你应该用\bhi\b.*\bLucy\b。
这里,.是另一个元字符,匹配除了换行符以外的任意字符。同样是元字符,不过它代表的不是字符,也不是位置,而是数量——它指定前边的内容可以连续重复使用任意次以使整个表达式得到匹配。因此,.连在一起就意味着任意数量的不包含换行的字符。现在`\bhi\b.\bLucy\b`的意思就很明显了:先是一个单词hi,然后是任意个任意字符(但不能是换行),最后是Lucy这个单词。
换行符就是’\n’,ASCII编码为10(十六进制0x0A)的字符。
如果同时使用其它元字符,我们就能构造出功能更强大的正则表达式。
比如下面这个例子:
0\d\d-\d\d\d\d\d\d\d\d匹配这样的字符串:以0开头,然后是两个数字,然后是一个连字号“-”,最后是8个数字(也就是中国的电话号码。当然,这个例子只能匹配区号为3位的情形)。
这里的\d是个新的元字符,匹配一位数字(0,或1,或2,或……)。-不是元字符,只匹配它本身——连字符(或者减号,或者中横线,或者随你怎么称呼它)。
为了避免那么多烦人的重复,我们也可以这样写这个表达式:0\d{2}-\d{8}。这里\d后面的{2}({8})的意思是前面\d必须连续重复匹配2次(8次)。
#测试正则表达式
如果你不觉得正则表达式很难读写的话,要么你是一个天才,要么,你不是地球人。
正则表达式的语法很令人头疼,即使对经常使用它的人来说也是如此。
不同的环境下正则表达式的一些细节是不相同的,请参考该页面 (opens new window)的说明来测试正则。
#核心概念
#元字符
现在你已经知道几个很有用的元字符了,如\b,.,*,还有\d.正则表达式里还有更多的元字符,比如\s匹配任意的空白符,包括空格,制表符(Tab),换行符,中文全角空格等。\w匹配字母或数字或下划线或汉字等。
对中文/汉字的特殊处理是由.Net提供的正则表达式引擎支持的,其它环境下的具体情况请查看相关文档。
下面来看看更多的例子:
\ba\w\b匹配以字母a开头的单词——先是某个单词开始处(\b),然后是字母a,然后是任意数量的字母或数字(\w),最后是单词结束处(\b)。
\d+匹配1个或更多连续的数字。这里的+是和类似的元字符,不同的是匹配重复任意次(可能是0次),而+则匹配重复1次或更多次。
\b\w{6}\b 匹配刚好6个字符的单词。
好吧,现在我们说说正则表达式里的单词是什么意思吧:就是不少于一个的连续的
\w。不错,这与学习英文时要背的成千上万个同名的东西的确关系不大 😃
| 代码 | 说明 |
|---|---|
. |
匹配除换行符以外的任意字符 |
\w |
匹配字母或数字或下划线或汉字 |
\s |
匹配任意的空白符 |
\d |
匹配数字 |
\b |
匹配单词的开始或结束 |
^ |
匹配字符串的开始 |
$ |
匹配字符串的结束 |
元字符^(和数字6在同一个键位上的符号)和$都匹配一个位置,这和\b有点类似。^匹配你要用来查找的字符串的开头,$匹配结尾。
这两个代码在验证输入的内容时非常有用,比如一个网站如果要求你填写的QQ号必须为5位到12位数字时,可以使用:
^\d{5,12}$。
这里的{5,12}和前面介绍过的{2}是类似的,只不过{2}匹配只能不多不少重复2次,{5,12}则是重复的次数不能少于5次,不能多于12次,否则都不匹配。
因为使用了^和$,所以输入的整个字符串都要用来和\d{5,12}来匹配,也就是说整个输入必须是5到12个数字,因此如果输入的QQ号能匹配这个正则表达式的话,那就符合要求了。
和忽略大小写的选项类似,有些正则表达式处理工具还有一个处理多行的选项。如果选中了这个选项,^和$的意义就变成了匹配行的开始处和结束处。
正则表达式引擎通常会提供一个“测试指定的字符串是否匹配一个正则表达式”的方法,如JavaScript里的RegExp.test()方法或.NET里的Regex.IsMatch()方法。这里的匹配是指是字符串里有没有符合表达式规则的部分。如果不使用^和$的话,对于\d{5,12}而言,使用这样的方法就只能保证字符串里包含5到12连续位数字,而不是整个字符串就是5到12位数字。
#字符转义
如果你想查找元字符本身的话,比如你查找.,或者*,就出现了问题:你没办法指定它们,因为它们会被解释成别的意思。这时你就得使用\来取消这些字符的特殊意义。因此,你应该使用\.和\*。当然,要查找\本身,你也得用.
例如:toimc\.com匹配toimc.com,C:\\Windows匹配C:\Windows。
#重复
你已经看过了前面的*,+,{2},{5,12}这几个匹配重复的方式了。下面是正则表达式中所有的限定符(指定数量的代码,例如*,{5,12}等):
| 代码/语法 | 说明 |
|---|---|
* |
重复零次或更多次 |
+ |
重复一次或更多次 |
| ? | 重复零次或一次 |
{n} |
重复n次 |
{n,} |
重复n次或更多次 |
{n,m} |
重复n到m次 |
下面是一些使用重复的例子:
Windows\d+匹配Windows后面跟1个或更多数字
^\w+匹配一行的第一个单词(或整个字符串的第一个单词,具体匹配哪个意思得看选项设置)
#字符类
要想查找数字,字母或数字,空白是很简单的,因为已经有了对应这些字符集合的元字符,但是如果你想匹配没有预定义元字符的字符集合(比如元音字母a,e,i,o,u),应该怎么办?
很简单,你只需要在方括号里列出它们就行了,像[aeiou]就匹配任何一个英文元音字母,[.?!]匹配标点符号(.或?或!)。
我们也可以轻松地指定一个字符范围,像[0-9]代表的含意与\d就是完全一致的:一位数字;同理[a-z0-9A-Z_]也完全等同于\w(如果只考虑英文的话)。
下面是一个更复杂的表达式:\(?0\d{2}[) -]?\d{8}。
这个表达式可以匹配几种格式的电话号码,像(010)88886666,或022-22334455,或02912345678等。我们对它进行一些分析吧:首先是一个转义字符(,它能出现0次或1次(?),然后是一个0,后面跟着2个数字(\d{2}),然后是)或-或空格中的一个,它出现1次或不出现(?),最后是8个数字(\d{8})。
#分枝条件
不幸的是,刚才那个表达式也能匹配010)12345678或(022-87654321这样的“不正确”的格式。要解决这个问题,我们需要用到分枝条件。正则表达式里的分枝条件指的是有几种规则,如果满足其中任意一种规则都应该当成匹配,具体方法是用|把不同的规则分隔开。听不明白?没关系,看例子:
0\d{2}-\d{8}|0\d{3}-\d{7}这个表达式能匹配两种以连字号分隔的电话号码:一种是三位区号,8位本地号(如010-12345678),一种是4位区号,7位本地号(0376-2233445)。\(0\d{2}\)[- ]?\d{8}|0\d{2}[- ]?\d{8}这个表达式匹配3位区号的电话号码,其中区号可以用小括号括起来,也可以不用,区号与本地号间可以用连字号或空格间隔,也可以没有间隔。你可以试试用分枝条件把这个表达式扩展成也支持4位区号的。
\d{5}-\d{4}|\d{5}这个表达式用于匹配美国的邮政编码。美国邮编的规则是5位数字,或者用连字号间隔的9位数字。之所以要给出这个例子是因为它能说明一个问题:使用分枝条件时,要注意各个条件的顺序。
如果你把它改成\d{5}|\d{5}-\d{4}的话,那么就只会匹配5位的邮编(以及9位邮编的前5位)。
原因是匹配分枝条件时,将会从左到右地测试每个条件,如果满足了某个分枝的话,就不会去再管其它的条件了。
#分组
我们已经提到了怎么重复单个字符(直接在字符后面加上限定符就行了);但如果想要重复多个字符又该怎么办?
你可以用小括号来指定子表达式(也叫做分组),然后你就可以指定这个子表达式的重复次数了,你也可以对子表达式进行其它一些操作(后面会有介绍)。
(\d{1,3}\.){3}\d{1,3}是一个简单的IP地址匹配表达式。
要理解这个表达式,请按下列顺序分析它:
\d{1,3}匹配1到3位的数字-(\d{1,3}\.){3}匹配三位数字加上一个英文句号(这个整体也就是这个分组)重复3次- 最后再加上一个一到三位的数字(\d{1,3})。
不幸的是,它也将匹配256.300.888.999这种不可能存在的IP地址。
如果能使用算术比较的话,或许能简单地解决这个问题,但是正则表达式中并不提供关于数学的任何功能,所以只能使用冗长的分组,选择,字符类来描述一个正确的IP地址:((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)。
理解这个表达式的关键是理解2[0-4]\d|25[0-5]|[01]?\d\d?,这里我就不细说了。
IP地址中每个数字都不能大于255. 经常有人问, 01.02.03.04 这样前面带有0的数字, 是不是正确的IP地址呢?
答案是: 是的, IP 地址里的数字可以包含有前导 0 (leading zeroes).
#反义
有时需要查找不属于某个能简单定义的字符类的字符。比如想查找除了数字以外,其它任意字符都行的情况,这时需要用到反义:
| 代码/语法 | 说明 |
|---|---|
\W |
匹配任意不是字母,数字,下划线,汉字的字符 |
\S |
匹配任意不是空白符的字符 |
\D |
匹配任意非数字的字符 |
\B |
匹配不是单词开头或结束的位置 |
[^x] |
匹配除了x以外的任意字符 |
[^aeiou] |
匹配除了aeiou这几个字母以外的任意字符 |
例子:\S+匹配不包含空白符的字符串。
<a[^>]+>匹配用尖括号括起来的以a开头的字符串。
#后向引用
使用小括号指定一个子表达式后,匹配这个子表达式的文本(也就是此分组捕获的内容)可以在表达式或其它程序中作进一步的处理。
默认情况下,每个分组会自动拥有一个组号,规则是:从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。
呃……其实,组号分配还不像我刚说得那么简单:
- 分组0对应整个正则表达式
- 实际上组号分配过程是要从左向右扫描两遍的:第一遍只给未命名组分配,第二遍只给命名组分配--因此所有命名组的组号都大于未命名的组号
- 你可以使用(?:exp)这样的语法来剥夺一个分组对组号分配的参与权.
后向引用用于重复搜索前面某个分组匹配的文本。
例如,\1代表分组1匹配的文本。难以理解?请看示例:
\b(\w+)\b\s+\1\b可以用来匹配重复的单词,像go go, 或者kitty kitty。这个表达式首先是一个单词,也就是单词开始处和结束处之间的多于一个的字母或数字(\b(\w+)\b),这个单词会被捕获到编号为1的分组中,然后是1个或几个空白符(\s+),最后是分组1中捕获的内容(也就是前面匹配的那个单词)(\1)。
你也可以自己指定子表达式的组名。要指定一个子表达式的组名,请使用这样的语法:(?<Word>\w+)(或者把尖括号换成’也行:(?'Word'\w+)),这样就把\w+的组名指定为Word了。要反向引用这个分组捕获的内容,你可以使用\k<Word>,所以上一个例子也可以写成这样:\b(?<Word>\w+)\b\s+\k<Word>\b。
使用小括号的时候,还有很多特定用途的语法。
下面列出了最常用的一些:
| 分类 | 代码/语法 | 说明 |
|---|---|---|
| 捕获 | (exp) |
匹配exp,并捕获文本到自动命名的组里 |
(?<name>exp) |
匹配exp,并捕获文本到名称为name的组里,也可以写成(?'name'exp) |
|
(?:exp) |
匹配exp,不捕获匹配的文本,也不给此分组分配组号 | |
| 零宽断言 | (?=exp) |
匹配exp前面的位置 |
(?<=exp) |
匹配exp后面的位置 | |
(?!exp) |
匹配后面跟的不是exp的位置 | |
(?<!exp) |
匹配前面不是exp的位置 | |
| 注释 | (?#comment) |
这种类型的分组不对正则表达式的处理产生任何影响,用于提供注释让人阅读 |
我们已经讨论了前两种语法。第三个(?:exp)不会改变正则表达式的处理方式,只是这样的组匹配的内容不会像前两种那样被捕获到某个组里面,也不会拥有组号。“我为什么会想要这样做?”——好问题,你觉得为什么呢?
#零宽断言
接下来的四个用于查找在某些内容(但并不包括这些内容)之前或之后的东西,也就是说它们像\b,^,$那样用于指定一个位置,这个位置应该满足一定的条件(即断言),因此它们也被称为零宽断言。最好还是拿例子来说明吧:
断言用来声明一个应该为真的事实。正则表达式中只有当断言为真时才会继续进行匹配。
(?=exp)也叫零宽度正预测先行断言,它断言自身出现的位置的后面能匹配表达式exp。比如\b\w+(?=ing\b),匹配以ing结尾的单词的前面部分(除了ing以外的部分),如查找I’m singing while you’re dancing.时,它会匹配sing和danc。(?<=exp)也叫零宽度正回顾后发断言,它断言自身出现的位置的前面能匹配表达式exp。比如(?<=\bre)\w+\b会匹配以re开头的单词的后半部分(除了re以外的部分),例如在查找reading a book时,它匹配ading。
假如你想要给一个很长的数字中每三位间加一个逗号(当然是从右边加起了),你可以这样查找需要在前面和里面添加逗号的部分:((?<=\d)\d{3})+\b,用它对1234567890进行查找时结果是234567890。
下面这个例子同时使用了这两种断言:(?<=\s)\d+(?=\s)匹配以空白符间隔的数字(再次强调,不包括这些空白符)。
#负向零宽断言
前面我们提到过怎么查找不是某个字符或不在某个字符类里的字符的方法(反义)。
但是如果我们只是想要确保某个字符没有出现,但并不想去匹配它时怎么办?例如,如果我们想查找这样的单词–它里面出现了字母q,但是q后面跟的不是字母u,我们可以尝试这样:\b\w*q[^u]\w*\b匹配包含后面不是字母u的字母q的单词。
但是如果多做测试(或者你思维足够敏锐,直接就观察出来了,你会发现,如果q出现在单词的结尾的话,像Iraq,Benq,这个表达式就会出错。
这是因为[^u]总要匹配一个字符,所以如果q是单词的最后一个字符的话,后面的[^u]将会匹配q后面的单词分隔符(可能是空格,或者是句号或其它的什么),后面的\w*\b将会匹配下一个单词,于是\b\w*q[^u]\w*\b就能匹配整个Iraq fighting。负向零宽断言能解决这样的问题,因为它只匹配一个位置,并不消费任何字符。现在,我们可以这样来解决这个问题:\b\w*q(?!u)\w*\b。
零宽度负预测先行断言(?!exp),断言此位置的后面不能匹配表达式exp。
例如:\d{3}(?!\d)匹配三位数字,而且这三位数字的后面不能是数字;\b((?!abc)\w)+\b匹配不包含连续字符串abc的单词。
同理,我们可以用(?<!exp),零宽度负回顾后发断言来断言此位置的前面不能匹配表达式exp:(?<![a-z])\d{7}匹配前面不是小写字母的七位数字。
一个更复杂的例子:(?<=<(\w+)>).*(?=<\/\1>)匹配不包含属性的简单HTML标签内里的内容。(?<=<(\w+)>)指定了这样的前缀:被尖括号括起来的单词(比如可能是<b>),然后是.*(任意的字符串),最后是一个后缀(?=<\/\1>)。注意后缀里的/,它用到了前面提过的字符转义;\1则是一个反向引用,引用的正是捕获的第一组,前面的(\w+)匹配的内容,这样如果前缀实际上是<b>的话,后缀就是</b>了。整个表达式匹配的是<b>和</b>之间的内容(再次提醒,不包括前缀和后缀本身)。
#注释
小括号的另一种用途是通过语法(?#comment)来包含注释。例如:2[0-4]\d(?#200-249)|25[0-5](?#250-255)|[01]?\d\d?(?#0-199)。
要包含注释的话,最好是启用“忽略模式里的空白符”选项,这样在编写表达式时能任意的添加空格,Tab,换行,而实际使用时这些都将被忽略。启用这个选项后,在#后面到这一行结束的所有文本都将被当成注释忽略掉。例如,我们可以前面的一个表达式写成这样:
|
#贪婪与懒惰
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。以这个表达式为例:a.*b,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索aabab的话,它会匹配整个字符串aabab。这被称为贪婪匹配。
有时,我们更需要懒惰匹配,也就是匹配尽可能少的字符。前面给出的限定符都可以被转化为懒惰匹配模式,只要在它后面加上一个问号?。这样.*?就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。现在看看懒惰版的例子吧:
a.*?b匹配最短的,以a开始,以b结束的字符串。如果把它应用于aabab的话,它会匹配aab(第一到第三个字符)和ab(第四到第五个字符)。
为什么第一个匹配是aab(第一到第三个字符)而不是ab(第二到第三个字符)?简单地说,因为正则表达式有另一条规则,比懒惰/贪婪规则的优先级更高:最先开始的匹配拥有最高的优先权——The match that begins earliest wins。
| 代码/语法 | 说明 |
|---|---|
*? |
重复任意次,但尽可能少重复 |
+? |
重复1次或更多次,但尽可能少重复 |
?? |
重复0次或1次,但尽可能少重复 |
{n,m}? |
重复n到m次,但尽可能少重复 |
{n,}? |
重复n次以上,但尽可能少重复 |
#处理选项
上面介绍了几个选项如忽略大小写,处理多行等,这些选项能用来改变处理正则表达式的方式。下面是.Net中常用的正则表达式选项:
| 名称 | 说明 |
|---|---|
| IgnoreCase(忽略大小写) | 匹配时不区分大小写。 |
| Multiline(多行模式) | 更改^和$的含义,使它们分别在任意一行的行首和行尾匹配,而不仅仅在整个字符串的开头和结尾匹配。(在此模式下,$的精确含意是:匹配\n之前的位置以及字符串结束前的位置.) |
| Singleline(单行模式) | 更改.的含义,使它与每一个字符匹配(包括换行符\n)。 |
| IgnorePatternWhitespace(忽略空白) | 忽略表达式中的非转义空白并启用由#标记的注释。 |
| ExplicitCapture(显式捕获) | 仅捕获已被显式命名的组。 |
在C#中,你可以使用Regex(String, RegexOptions)构造函数 (opens new window)来设置正则表达式的处理选项。如:Regex regex = new Regex(@”\ba\w{6}\b”, RegexOptions.IgnoreCase);
2019/06:只有基于 Webkit/Chromium 的浏览器(如 Chrome, Safari等)才支持 dotAll 选项。
一个经常被问到的问题是:是不是只能同时使用多行模式和单行模式中的一种?
答案是:不是。这两个选项之间没有任何关系,除了它们的名字比较相似(以至于让人感到疑惑)以外。事实上,为了避免混淆,在最新的 JavaScript 中,单行模式其实名叫 dotAll,意为点可以匹配所有字符,然而在指定该选项时,用的还是 Singleline 的首字母 s.
#平衡组/递归匹配
有时我们需要匹配像( 100 ( 50 + 15 ) )这样的可嵌套的层次性结构,这时简单地使用\(.+\)则只会匹配到最左边的左括号和最右边的右括号之间的内容(这里我们讨论的是贪婪模式,懒惰模式也有下面的问题)。假如原来的字符串里的左括号和右括号出现的次数不相等,比如( 5 / ( 3 + 2 ) ) )*,那我们的匹配结果里两者的个数也不会相等。有没有办法在这样的字符串里匹配到最长的,配对的括号之间的内容呢?
这里介绍的平衡组语法是由.Net Framework支持的;其它语言/库不一定支持这种功能,或者支持此功能但需要使用不同的语法。
为了避免(和(把你的大脑彻底搞糊涂,我们还是用尖括号代替圆括号吧。现在我们的问题变成了如何把xx <aa <bbb> <bbb> aa> yy这样的字符串里,最长的配对的尖括号内的内容捕获出来?
这里需要用到以下的语法构造:
(?'group')把捕获的内容命名为group,并压入堆栈(Stack)(?'-group')从堆栈上弹出最后压入堆栈的名为group的捕获内容,如果堆栈本来为空,则本分组的匹配失败(?(group)yes|no)如果堆栈上存在以名为group的捕获内容的话,继续匹配yes部分的表达式,否则继续匹配no部分(?!)零宽负向先行断言,由于没有后缀表达式,试图匹配总是失败
我们需要做的是每碰到了左括号,就在压入一个”Open”,每碰到一个右括号,就弹出一个,到了最后就看看堆栈是否为空--如果不为空那就证明左括号比右括号多,那匹配就应该失败。正则表达式引擎会进行回溯(放弃最前面或最后面的一些字符),尽量使整个表达式得到匹配。
|
平衡组的一个最常见的应用就是匹配HTML,下面这个例子可以匹配嵌套的<div>标签:<div[^>]*>[^<>]*(((?'Open'<div[^>]*>)[^<>]*)+((?'-Open'</div>)[^<>]*)+)*(?(Open)(?!))</div>.
如果你不是一个程序员(或者你自称程序员但是不知道堆栈是什么东西),你就这样理解上面的三种语法吧:第一个就是在黑板上写一个”group”,第二个就是从黑板上擦掉一个”group”,第三个就是看黑板上写的还有没有”group”,如果有就继续匹配yes部分,否则就匹配no部分。
#扩展知识
上边已经描述了构造正则表达式的大量元素,但是还有很多没有提到的东西。
下面是一些未提到的元素的列表,包含语法和简单的说明。你可以在网上找到更详细的参考资料来学习它们–当你需要用到它们的时候。如果你安装了MSDN Library,你也可以在里面找到.Net下正则表达式详细的文档。这里的介绍很简略,如果你需要更详细的信息,而又没有在电脑上安装MSDN Library,可以查看关于正则表达式语言元素的MSDN在线文档 (opens new window)。
| 代码/语法 | 说明 | |
|---|---|---|
\a |
报警字符(打印它的效果是电脑嘀一声) | |
\b |
通常是单词分界位置,但如果在字符类里使用代表退格 | |
\t |
制表符,Tab | |
\r |
回车 | |
\v |
竖向制表符 | |
\f |
换页符 | |
\n |
换行符 | |
\e |
Escape | |
\0nn |
ASCII代码中八进制代码为nn的字符 | |
\xnn |
ASCII代码中十六进制代码为nn的字符 | |
\unnnn |
Unicode代码中十六进制代码为nnnn的字符 | |
\cN |
ASCII控制字符。比如\cC代表Ctrl+C | |
\A |
字符串开头(类似^,但不受处理多行选项的影响) | |
\Z |
字符串结尾或行尾(不受处理多行选项的影响) | |
\z |
字符串结尾(类似$,但不受处理多行选项的影响) | |
\G |
当前搜索的开头 | |
\p{name} |
Unicode中命名为name的字符类,例如\p{IsGreek} | |
(?>exp) |
贪婪子表达式 | |
(?<x>-<y>exp) |
平衡组 | |
(?im-nsx:exp) |
在子表达式exp中改变处理选项 | |
(?im-nsx) |
为表达式后面的部分改变处理选项 | |
| `(?(exp)yes\ | no)` | 把exp当作零宽正向先行断言,如果在这个位置能匹配,使用yes作为此组的表达式;否则使用no |
(?(exp)yes) |
同上,只是使用空表达式作为no | |
| `(?(name)yes\ | no)` | 如果命名为name的组捕获到了内容,使用yes作为表达式;否则使用no |
(?(name)yes) |
同上,只是使用空表达式作为no |